
Documents Live, a web authoring and publishing system
If you see this, something is wrong
Table of contents
First published on Friday, Apr 4, 2025 and last modified on Thursday, Apr 10, 2025 by François Chaplais.
Published version: 10.48550/arXiv.2503.07324
Max Planck Institute for Intelligent Systems, 72076 Tübingen, Germany Email
Automatic Control Laboratory, ETH Zürich, 8092 Zürich, Switzerland Email
Automatic Control Laboratory, ETH Zürich, 8092 Zürich, Switzerland Email
Max Planck Institute for Intelligent Systems, 72076 Tübingen, Germany Email
Stochastic optimization, distribution shift, dynamics, gradient method, feedback loop
Abstract
Distribution shifts have long been regarded as troublesome external forces that a decision-maker should either counteract or conform to. An intriguing feedback phenomenon termed decision dependence arises when the deployed decision affects the environment and alters the data-generating distribution. In the realm of performative prediction, this is encoded by distribution maps parameterized by decisions due to strategic behaviors. In contrast, we formalize an endogenous distribution shift as a feedback process featuring nonlinear dynamics that couple the evolving distribution with the decision. Stochastic optimization in this dynamic regime provides a fertile ground to examine the various roles played by dynamics in the composite problem structure. To this end, we develop an online algorithm that achieves optimal decision-making by both adapting to and shaping the dynamic distribution. Throughout the paper, we adopt a distributional perspective and demonstrate how this view facilitates characterizations of distribution dynamics and the optimality and generalization performance of the proposed algorithm. We showcase the theoretical results in an opinion dynamics context, where an opportunistic party maximizes the affinity of a dynamic polarized population, and in a recommender system scenario, featuring performance optimization with discrete distributions in the probability simplex.
1 Introduction
Modern decision-making problems in machine learning, operations research, and control often feature intrinsic randomness, streaming data, and large scales. At the heart of such decision-making pipelines is stochastic optimization, which incorporates random objective functions, constraints, and algorithms with random iterative updates [12]. Stochastic optimization often leverages knowledge, estimates, or samples of data distributions to disentangle the complex coupling between randomness and decisions, achieve fast processing and adaptation, and navigate vast search spaces to arrive at optimal solutions.
Classical stochastic optimization assumes that the random variables in a problem obey some fixed distributions. In practice, however, distribution shifts are inevitable and can be both exogenous and endogenous. Exogenous distribution shifts are largely due to changing environmental conditions, e.g., parameter shifts in online estimation or an arbitrary new distribution selected by an adversary. In this regard, online stochastic optimization emphasizes adaptation by sequentially drawing new samples and adjusting decisions [13, 14].
Endogenous distribution shifts acknowledge the influence of a decision-maker on the data-generating distribution. This influence, i.e., decision dependence, contributes to a closed loop, whereby the decision and the data distribution interrelate in a repeated decision-making scenario. Various issues cause endogenous shifts and lead to different problem formulations, such as a reinforcement learning agent interacting with its environment, a dominant decision-maker being a price maker in a market, or a content recommender shaping user preferences, among others. In two-stage stochastic programming, models of how first-stage decisions alter distributions of random quantities in the second stage are discussed in [1]. Performative prediction [15, 16] tackles optimization involving distributions in the form of a general map parameterized by decisions. These parameterized distributions are inspired by strategic behaviors, where individuals intentionally modify features as a response to the deployed predictive model. A predominant and a priori assumption is on Lipschitz distribution shifts, namely, a bounded change of decisions brings about a bounded change of the resulting distributions.
The aforementioned works largely capture decision dependence through (static) parameterized maps. In contrast, we address decision-making under endogenous distribution shifts represented by a broad class of nonlinear dynamics. This explicit formulation of distribution dynamics is motivated by the interactive feedback loop between a decision-maker and an evolving distribution, exemplified by problems in recommender systems [17, 18, 19] and opinion dynamics [20]. Each individual random variable (representing feature, preference, or intrinsic uncertainty) follows latent dynamics coupling the historical value with the current decision. Through distribution dynamics, the decision affects the individual variable and, thus, the overall distribution. This type of decision dependence features a nonlinear mixture of sequential decisions and non-stationary distributions, which render the associated stochastic optimization problem challenging and fundamentally different from performative prediction. Our formulation is also closely aligned with the mean-field setting [21]. However, major differences exist in terms of the performance measure, the structure of decisions, and the specifications of dynamics and distributions, see (1.3) for more accounts.
By exploiting the structure of distribution dynamics, we will provide fine-grained analysis of distribution shifts, design iterative stochastic algorithms tailored to this dynamic setting, and establish guarantees of optimality and generalization in terms of this decision-dependent stochastic problem. Our design and analysis benefit from a distributional perspective, building connections between stochastic optimization, nonlinear control, and metric probability spaces.
1.1 Motivations
We investigate optimal decision-making under endogenous distribution shifts with latent dynamics. These shifts arise from the dynamic interaction of a decision-maker and an evolving distribution. We present a motivating example in the domains of opinion dynamics.

Example 1 (Ideology tailored to a polarized population)
Consider the interaction between a political party (or a candidate) and a large population. The party is opportunistic with the aim of gaining power by picking an ideology that aligns with the majority and grants it the most votes.
Let the adopted ideology of the party and the position (or the preference state) of a random individual in the population at time \( k\) be denoted by \( q_k \in \mathbb{R}^m\) and \( p_k \in \mathbb{R}^m\) , respectively. Each coordinate of \( q_k\) or \( p_k\) indicates a liberal or conservative opinion on an agenda, e.g., taxes, health care, or immigration. The evolution of \( p_k\) driven by \( q_k\) is
(1)
where \( g: \mathbb{R}^m \times \mathbb{R}^m \times \mathbb{R}^m \to \mathbb{R}\) specifies the dynamics, and \( \mu_d\) is the distribution of the initial state. For instance, the classical Friedkin-Johnsen model [20] reads \( p_{k+1} = \Lambda_1 W p_k + \Lambda_2 q_k + (I-\Lambda_1-\Lambda_2) p_0\) , where \( I \in \mathbb{R}^{m\times m}\) is the identity matrix, and \( \Lambda_1,\Lambda_2,W \in \mathbb{R}^{m\times m}\) are weight matrices. The nonlinear polarized model [10, 11] is \( p_{k+1} \propto \lambda p_k + (1-\lambda) p_0 + \sigma (p_k^{\top} q_k)q_k\) , and \( p_k\) is always normalized, i.e., \( \forall k, \|p_k\|=1\) . At every time \( k\) , the party collects samples from the population and opportunistically adjusts the ideology \( q_k\) . To maximize the votes at an upcoming election, the steady-state population-wide affinity that the party intends to maximize is \( \mathrm{ \mathbb{E} }_{p_\textup{ss}}[p_\textup{ss}^{\top} q]\) , where \( p_\textup{ss}\) satisfies the fixed-point equation \( p_\textup{ss} = g(p_\textup{ss},q,p_0)\) [22, 23]. Since \( p_\textup{ss}\) is hardly available, the party uses the current opinion distribution of \( p_k\) , estimated by polls (i.e., sampling), for decision-making.
Due to the dynamics (1) and the picked ideology \( q_{k-1}\) , the distribution followed by \( p_k\) changes constantly. The latter in turn affects the decision-making based on \( p_k\) and causes a feedback loop, see (1). The classical paradigm of repeated sampling and retraining helps to adapt to this distribution shift. Nonetheless, this paradigm can suffer from sub-optimality because the dependence of the steady-state position \( p_\textup{ss}\) on the decision \( q\) is ignored. In (5), we will review this motivating example and provide a detailed formulation, analysis, and numerical results.
Aligned with this motivating example, here we explore general stochastic optimization with endogenous distribution shifts arising from the interaction between a decision-maker and a dynamic distribution, see (1) for an illustration. This setup involves several major challenges. First, the largely unknown distribution dynamics exclude an offline strategy based on the exact (re)formulation of the decision-making problem. Second, while the paradigm of repeated sampling and retraining in performative prediction facilitates adaptation (see (1.3)), achieving optimality beyond performative stability requires anticipating how the decision affects the distribution and applying proactive adjustments. Finally, the dynamic setup restricts us from sampling from the steady-state distribution corresponding to the decision, which is the very distribution we care about while evaluating the overall performance. In this paper, we will address these challenges by developing and analyzing an online stochastic algorithm tailored to this dynamic setting.
1.2 Contributions
We are motivated by applications where a decision-maker drives a constantly evolving distribution and aims to optimize the distribution-level performance. We formulate a decision-dependent stochastic problem featuring endogenous distribution shifts with latent dynamics. For this general and dynamic setting, we adopt a distributional perspective at the intersection of stochastic optimization, nonlinear control, and metric probability spaces and present the following contributions.
- We characterize the distribution shift via the contracting coefficient of distribution dynamics and the change of decisions. To this end, we use as the main metric the Wasserstein distance [5] between the current distribution and its steady-state distribution induced by the decision. This metric plays a similar (albeit not necessarily the same) role as a Lyapunov function in control theory [24]. Although the exact value of such a Wasserstein distance can be elusive, the recursive inequality related to this metric sheds light on the dynamic evolution of the distribution.
- We propose an online stochastic algorithm that leverages samples from the current distribution and takes into account the composite structure of the problem due to dynamics. The iterative update direction consists of two terms. One term focuses on adaptation, and the most recent samples are exploited to adjust decisions. The other term actively shapes future distributions by anticipating the sensitivity of the distribution with respect to the decision, thereby informing optimal decision-making. Notably, our algorithm does not resort to a world model of the dynamic distribution; instead, the only adopted information is the so-called sensitivity, which is easily learnable in many scenarios.
- We establish optimality guarantees of the proposed algorithm in a nonconvex setting. In the face of dynamics and the composite structure, the convergence measure (i.e., the expected second moment of gradients) enjoys a favorable \( \mathcal{O}(1/\sqrt{T})\) rate, where \( T\) is the total number of iterations. This rate is as sharp as that of stochastic gradient descent for static nonconvex problems without decision dependence. Further, we provide high-probability convergence guarantees for a single run of the proposed algorithm. The key insight is to synthesize the coupled evolution of the aforementioned Wasserstein metric and the convergence measure, which correspond to the dynamic distribution and the iterative algorithm, respectively.
- We quantify the finite-sample generalization performance. We explore how the decisions obtained based on an empirical distribution with finite samples will generalize to the original distribution-level problem. We demonstrate that the generalization measure scales polynomially with the number of samples and the number of iterations, as well as polylogarithmically with the inverse of the failure probability. These results are built on the measure concentration argument and the characterization of the distribution shift, illustrating the benefits of our distributional perspective.
- We illustrate the aforementioned results with practical examples, where an opportunistic party maximizes the affinity of a polarized dynamic population, and a recommender optimizes performance by interacting with a user. In the first setup, the population is modeled as a continuous distribution, whereas in the second example, the user is represented by a discrete distribution evolving in the probability simplex. We demonstrate that respecting the composite problem structure due to decision dependence is crucial for achieving fast convergence and improved optimality.
1.3 Related work
A multitude of works investigate the roles of distribution shifts and decision dependence in machine learning, optimization, and control. We provide a concise review of their setups and foci.
In applications, data-generating distributions can change because of various factors, e.g., non-stationary environment, unknown covariate shifts, and adversarial effects. There are two predominant strategies for addressing distribution shifts. One strategy pursues robustness against potential perturbations to distributions. This falls under the umbrella of distributionally robust optimization [25, 26] and is achieved by optimizing the worst-case cost over a so-called ambiguity set, i.e., the family of distributions that are close to the true distribution under certain metrics. Further, in two-stage stochastic programming, the first-stage decision may change the uncertain distribution in the second stage, thereby producing a decision-dependent ambiguity set [1]. Tractable reformulations are derived in [2, 3] to disentangle this dependence and obtain robust solutions.
In the face of constantly evolving distributions, a less conservative and more active strategy is to seek adaptation. Specifically, online stochastic optimization investigates an iterative loop whereby a decision-maker commits a decision, receives samples from a dynamic distribution as feedback [13, 14], and then generates a new decision. Such an online framework is versatile and particularly suitable to tackle exogenous distribution shifts, which are out of the influence of a decision-maker. Nonetheless, in terms of optimization subject to endogenous distribution shifts caused by decisions (see also the beginning of (1)), unique phenomena (e.g., the existence of equilibria and stability issues) arise, requiring tailored methods for this closed-loop setting. We delineate some representative works as follows.
Performative prediction studies optimization under decision-dependent distributions [15, 16]. A canonical example is strategic classification, where an individual deliberately modifies her feature in reaction to the deployed classifier, thereby gaining a more favorable classification result. Such endogenous distribution shifts are usually formalized as static distribution maps parameterized by decisions. This setup leads to a novel equilibrium notion termed performative stability, meaning the decision optimizes the objective given the specific distribution it induces. Through repeated sampling and retraining, various stochastic algorithms converge to performatively stable points [27, 28]. A stronger solution concept is performative optimality, requiring that the decision and the induced distribution together lead to an optimal objective value. Convergence to performatively optimal points is achieved with additional structural assumptions on the distribution map, e.g., it belongs to a linear location-scale family [29, 30, 31, 32] or an exponential family [33]. As a general, elegant, and tractable framework, performative prediction admits numerous extensions, including network scenarios with cooperative [34] or competing agents [31, 35], time-varying objectives [36, 37], saddle point minimax problems [38], and coupling constraints [32].
Our work is closely related to stateful performative prediction, which captures historical dependence and considers an evolving distribution that gradually settles at the stationary distribution map. Models of historical dependence include geometrically ergodic Markov chains [39] and geometric decay responses in the form of linear mixture [40, 41]. With Lipschitz distribution shifts assumed in the first place, the algorithms therein converge to performatively stable (albeit not necessarily optimal) points. In contrast, we formalize a decision-dependent distribution shift featuring a broad class of nonlinear dynamics mixing continuous decisions and state distributions. Moreover, we explicitly characterize the distribution shift through the Wasserstein metric [5] and link this shift with dynamics parameters and the change of decisions. We further establish convergence to locally optimal solutions given a nonconvex objective function involving the decision-dependent structure.
Along the line of performative decision-making, some recent works study the role of dynamics in the decision-dependent problem setup. Performative reinforcement learning [42] handles transition probability and reward functions relying on the deployed policy and finds a stable policy given cumulative rewards. Performative control in [59] addresses linear dynamics with policy-dependent state transition matrices and seeks a performatively stable control solution as a linear combination of states and disturbances. The framework of [4] represents the dynamics of a strategic population via a gradient flow in the Wasserstein space. The interconnection of this strategic population and a decision-maker results in coupled partial differential equations, which admit asymptotic convergence to optimal solutions for convex (or concave) energy functionals. In contrast, we characterize the distribution shift represented by general nonlinear dynamics. Furthermore, we offer insights into anticipating the sensitivity of the distribution shift, taking into account the composite structure due to dynamics in the algorithmic design, and achieving (locally) optimal decision-making in the context of nonconvex objectives. The incorporation of anticipating sensitivity to actively shape distributions is the distinguishing feature of our algorithm compared to the aforementioned performative methods.
Mean-field formulation abstracts the mutual influence in a vast homogeneous population by the interaction between a representative individual and an average density, i.e., the mean field [43]. This abstraction facilitates approximately solving an otherwise intractable multi-agent problem, wherein the joint states and actions may grow exponentially with the number of agents. The solutions to mean-field games or control are characterized by two coupled equations, namely, a forward equation for the evolving mean-field distribution and a backward equation associated with the individual value function. Classical approaches rely on the full knowledge of population dynamics and work under restrictive assumptions [21]. A recent trend is to apply reinforcement learning to learn models of dynamics [44], value functions, or policy functions [45], thereby obtaining Nash equilibrium or socially optimal policies. Different from the mean-field formulation, we examine a simplified case where individuals do not interact with one another. Nevertheless, we provide the following new insights. First, we require less information or learning effort related to distribution dynamics. Rather than constructing well-calibrated models, we only access steady-state sensitivity matrices corresponding to dynamics, which are easily learnable, see (2.2). Second, we explicitly characterize the distribution shift via dynamics parameters and the change of decisions. Finally, instead of analyzing a cumulative cost and a state-feedback policy, we seek optimal steady-state performance and a general decision vector. For the generic setting with nonconvex objectives and nonlinear dynamics, we quantify the local optimality of the obtained solutions.
Control in probability spaces addresses the formulation where the state of a system is a probability measure instead of a Euclidean vector [46]. This formulation facilitates the characterization of the evolving uncertainties in a system or the collective behavior of a population, both of which are intrinsically modeled via probability distributions [47, 18]. A typical example is distribution steering, i.e., driving the state distribution from an initial density to a target density in finite time with minimum energy control [46]. In this regard, tractable control strategies cross-fertilize insights from control theory (e.g., linear state-feedback structures) and optimal transport [e.g., transport map calculations, 5]. In contrast, we search for an optimal decision vector rather than a state feedback control policy. Further, we do not aim for a specific final distribution. Instead, we hope the decision, together with the distribution induced through the nonlinear dynamics, will lead to an optimal steady-state behavior.
In a broader context, our work aligns with feedback optimization [48, 49], which implements optimization iterations as a feedback controller, thereby regulating the steady-state behavior of a dynamical system. Nonetheless, in this paper we are concerned with distribution-level characterizations in a metric space of probability measures, which is drastically different from the system-theoretic analysis of feedback optimization in Euclidean space.
In summary, we capture the distribution shift arising from the dynamic evolution of a distribution driven by a decision-maker. Such dynamics are represented by a broad class of nonlinear equations encompassing continuous states and decisions. We propose and characterize an online stochastic algorithm that respects the composite problem structure due to dynamics, regulates the distribution flow, and yields locally optimal solutions to the overall nonconvex problem featuring decision dependence.
The remainder of this paper is structured as follows. (2) introduces preliminaries of the metric probability space and formulates the stochastic optimization problem involving dynamic decision-dependent distributions. (3) presents the intuitions and design of our online stochastic algorithm. In (4), we characterize the distribution dynamics and establish guarantees on the optimality and generalization performance of the proposed algorithm. (5) showcases an application in affinity maximization with a polarized population following (1), as well as another case study in a recommender system context involving discrete distributions. Finally, (6) concludes this paper and discusses future directions. All proofs are provided in the appendix.
2 Preliminaries and Problem Formulation
2.1 Metric space of probability measures
We review the background of a metric probability space and refer the readers to [5] for more details. Let \( \mathcal{P}(\mathbb{R}^m)\) be the space of Borel probability distributions on \( \mathbb{R}^m\) . Let \( \mathcal{P}_1(\mathbb{R}^m) \triangleq \big\{\mu \in \mathcal{P}(\mathbb{R}^m): \int_{\mathbb{R}^m} \|x\| \,\mathrm{d} \mu(x) < \infty \big\}\) be the space of distributions with finite absolute moments. The Dirac mass at point \( x \in \mathbb{R}^m\) is denoted by \( \delta_x\) , i.e., for any Borel set \( A \subseteq \mathbb{R}^m\) , \( \delta_x(A) = 1\) if \( x \in A\) and \( \delta_x(A) = 0\) otherwise. We use \( X \sim \mu\) to indicate that a random variable \( X\) is distributed according to \( \mu\) . The convolution of two distributions \( \mu, \nu \in \mathcal{P}_1(\mathbb{R}^m)\) is denoted by \( \mu * \nu\) . Specifically, if two random variables \( X\) and \( Y\) are independent and distributed according to \( \mu\) and \( \nu\) , respectively, then \( X+Y \sim \mu * \nu\) . The pushforward of a distribution \( \mu\) via a Borel map \( f: \mathbb{R}^{r} \to \mathbb{R}^m\) is represented by \( f_{\#}\mu\) , where \( (f_{\#} \mu)[A] \triangleq \mu[f^{-1}(A)]\) for every Borel set \( A \subseteq \mathbb{R}^m\) . In fact, if \( X \sim \mu\) , then \( f(X) \sim f_{\#} \mu\) . The identity map is \( \mathopen{}\mathrm{Id}\) .
Let \( \|z\|_P = \sqrt{z^\top P z}\) denote the weighted norm of a vector \( z \in \mathbb{R}^m\) , where \( P \in \mathbb{R}^{m\times m}\) is positive definite. Consider a metric space \( (\mathbb{R}^m, c)\) endowed with a continuous metric \( c : \mathbb{R}^m \times \mathbb{R}^m \to \mathbb{R}_{\geq 0}\) . Typical examples of \( c\) include the Euclidean distance \( c(x,y) = \|x-y\|\) , the weighted distance \( c(x,y) = \|x-y\|_P\) , and other distances defined by composite norms, where \( x,y \in \mathbb{R}^m\) . The type-\( 1\) Wasserstein distance \( W_1(\mu,\nu)\) between two distributions \( \mu, \nu \sim \mathcal{P}_1(\mathbb{R}^m) \) on \( (\mathbb{R}^m, c)\) is
(2)
where \( \Gamma(\mu,\nu)\) is the set of all joint distributions (i.e., couplings) with marginals \( \mu\) and \( \nu\) , see [5, Definition 6.1]. Intuitively, the Wasserstein distance is the minimum cost of transporting \( \mu\) onto \( \nu\) , where the cost of moving a unit mass from \( x\) to \( y\) is \( c(x,y)\) , and the available transport plan is represented by \( \gamma\) . The Wasserstein distance is a flexible and quantitative measure of the discrepancy between distributions, particularly when they have disjoint supports, such as when one distribution is continuous and the other is discrete.
2.2 Distribution dynamics
We generalize the motivating case study in (1) and consider the following distribution dynamics with continuous states
(3)
In (3), \( p_k \in \mathbb{R}^m\) is a random state at time \( k\) distributed according to \( \mu_k\) , i.e., \( p_k \sim \mu_k\) . The initial state \( p_0\) satisfies the distribution \( \mu_0 \in \mathcal{P}_1(\mathbb{R}^m)\) . Further, \( u \in \mathbb{R}^n\) is a decision (or an input) that influences each random state, and \( d \in \mathbb{R}^r\) following the distribution \( \mu_d \in \mathcal{P}_1(\mathbb{R}^r)\) is an exogenous input that remains constant during iterations. For instance, \( d\) can be a bias term (similar to the initial position in (1)), a disturbance, or a random parameter in a model of \( f\) . Each pair \( (p_0,d)\) is independently drawn from the joint distribution \( \alpha\) , and the first and the second marginals of \( \alpha\) are \( \mu_0\) and \( \mu_d\) , respectively. For instance, if \( p_0\) and \( d\) as well as \( \mu_0\) and \( \mu_d\) are the same (c.f. (1)), then \( \alpha = ( \mathopen{}\mathrm{Id}, \mathopen{}\mathrm{Id})_{\#} \mu_0\) ; if \( p_0\) and \( d\) are independent, then \( \alpha\) is the product measure \( \mu_0 \times \mu_d\) .
The distribution dynamics (3) feature decision dependence, in that the evolution of the distribution \( \mu_k\) is driven by the decision \( u_k\) . The status of this distribution will in turn determine the optimal decision for an optimal distribution-level behavior. Before we present the formal problem description, we specify some properties related to the dynamics (3). All these properties serve the purpose of characterization and analysis. Our online algorithm does not resort to the model \( f\) of the distribution dynamics; rather, it leverages samples and certain learnable sensitivities related to (3).
Assumption 1
The function \( f(p,u,d)\) is continuously differentiable, \( L_f^p\) -Lipschitz continuous in \( p\) with respect to the weighted norm \( \|\cdot\|_P\) , where \( P \in \mathbb{R}^{m\times m}\) is positive definite, \( L_fû\) -Lipschitz continuous in \( u\) with respect to \( \|\cdot\|\) , and \( L_f^d\) -Lipschitz continuous in \( d\) with respect to \( \|\cdot\|\) . Here, \( L_f^p \in (0,1)\) , \( L_fû > 0\) , and \( L_f^d > 0\) . There exists a continuously differentiable steady-state map \( h: \mathbb{R}^n \times \mathbb{R}^r \to \mathbb{R}^m\) such that \( h(u,d) = f(h(u,d),u,d)\) . Furthermore, \( \nabla_u h(u,d)\) is \( M_h^d\) -Lipschitz in \( d\) with respect to \( \|\cdot\|\) .
(1) implies that the dynamics (3) are contracting in \( p\) with respect to the weighted norm \( \|\cdot\|_P\) . The existence and conditioning of \( P\) (i.e., the so-called contraction metric) are known for incrementally exponentially stable nonlinear dynamics [50]. Based on the Lipschitz conditions of \( f\) , the Banach contraction theorem ensures that for a fixed input \( u\) (i.e., \( u_kū,\forall k \in \mathbb{N}_{+}\) ) and a specific exogenous input \( d\) , the dynamics (3) admit a unique steady state \( p_\textup{ss} = h(u,d)\) satisfying \( p_\textup{ss} = f(p_\textup{ss},u,d)\) . We can further establish that \( h\) is \( L_hû\) -Lipschitz in \( u\) and \( L_h^d\) -Lipschitz in \( d\) with respect to \( \|\cdot\|\) , where \( L_hû = L_fû\sqrt{\lambda_{\max}(P)/\lambda_{\min}(P)}/(1-L_f^p)\) and \( L_h^d = L_f^d\sqrt{\lambda_{\max}(P)/\lambda_{\min}(P)}/(1-L_f^p)\) , see the parametric contraction mapping principle [51, Theorem 1A.4] and also (5) in (A). The Lipschitz continuity of \( \nabla_u h(u,d)\) (i.e., the so-called sensitivity matrix) can be satisfied when \( f\) has bounded Hessians. As we will see in (2) below, stable linear dynamics naturally satisfy (1).
From a distribution-level perspective, all the steady-state samples \( p_\textup{ss}\) satisfy the following distribution \( \mu_\textup{ss}(u)\) that depends on \( u\) and \( \mu_d\)
(4)
where \( h(u,\cdot)_{\#} \mu_d\) denotes the pushforward of the distribution \( \mu_d\) via a Borel map \( h(u,\cdot): \mathbb{R}^r \to \mathbb{R}^m\) parameterized by the decision \( u\) . Let \( \nabla_u h(u,d) \in \mathbb{R}^{n\times m}\) be the steady-state sensitivity matrix of \( p_\textup{ss} = h(u,d)\) with respect to the decision \( u\) . It follows from the implicit function theorem [51, Theorem 1B.1] that
(5)
which holds in an open neighborhood of \( (u,d)\) . The sensitivity \( \nabla_u h(u,d)\) quantifies the rate of change of the steady-state sample \( p_\textup{ss}\) with respect to the decision \( u\) . While (5) may seem daunting at first glance, the sensitivity can be simplified in various scenarios. For instance, when the dynamics (3) are linear, the corresponding sensitivity becomes a constant matrix, see (2) below. If the exogenous input \( d\) is additive in (3), then the detailed form of (5) no longer involves \( d\) . More broadly, apart from invoking (5) based on the related knowledge of dynamics and parameters, we can exploit recursive estimation or identification techniques to construct (approximate) sensitivities, see [49, Sec. 3.3.1] in the context of widely adopted feedback optimization methods. Such a learnable sensitivity is the only model information on (3) used in our online algorithm. All the characterizations in (1) are for the sake of analysis, and the full world model (i.e., \( f\) ) of the distribution dynamics is not required.
In the following example, we review an important special case of (3), where the dynamics function is linear. We will see how (1) is justified and provide explicit expressions of the distribution \( \mu_k\) at time \( k\) and the steady-state distribution \( \mu_\textup{ss}(u)\) .
Example 2 (Linear distribution dynamics)
Suppose that each sample evolves by a linear dynamics equation \( p_k = f(p_{k-1},u_k,d) = A p_{k-1} + B u_k + Ed\) , where \( A \in \mathbb{R}^{m \times m}\) , \( B \in \mathbb{R}^{m\times n}\) , \( E \in \mathbb{R}^{m\times r}\) , and \( p_0 \sim \mu_0, d \sim \mu_d\) . Then, (1) is satisfied if \( A\) is Schur stable, i.e., \( \rho(A) < 1\) . Given a Schur stable matrix \( A\) and a positive definite \( Q \in \mathbb{R}^{m\times m}\) , there exists a unique positive definite matrix \( P \in \mathbb{R}^{m\times m}\) satisfying the Lyapunov equation \( A^{\top}PA - P + Q = 0\) [24]. Let \( \lambda_{\min}(Q) > 0\) and \( \lambda_{\max}(P) > 0\) denote the minimum eigenvalue of \( Q\) and the maximum eigenvalue of \( P\) , respectively. With the metric \( \|\cdot\|_P\) , for any \( p, \overline{p} \in \mathbb{R}^m\) , \( u \in \mathbb{R}^n\) , and \( d \in \mathbb{R}^r\) ,
where (a.1) follows from the aforementioned Lyapunov equation. In (a.2), we use
see also (5) in (A). Moreover, since \( Q-P = -A^\top PA\) is negative definite, we know \( \lambda_{\min}(Q) I \prec Q \prec P \prec \lambda_{\max}(P)I\) , and therefore \( \lambda_{\min}(Q)/\lambda_{\max}(P) \in (0,1)\) . Further, for any \( p \in \mathbb{R}^m\) , \( u, \overline{u} \in \mathbb{R}^n\) , and \( d \in \mathbb{R}^r\) ,
When the decision \( u\) is fixed (i.e., \( u_kū,\forall k\in \mathbb{N}_{+}\) ), the steady-state sample \( p_\textup{ss}\) is \( p_\textup{ss} = h(u,d) = (I-A)^{-1}(B u + E d)\) , and the map \( h\) is continuously differentiable. The steady-state sensitivity matrix is \( \nabla_u h(u,d) = [(I-A)^{-1}B]^\top\) , which is constant and independent of \( u\) and \( d\) . In applications, this sensitivity (in engineering lingo called the zero-frequency gain) can be learned from data of decisions and samples [49, Sec. 3.3.1]. Hence, (1) is satisfied.
Similar to [58, Proposition 18], the transient distribution \( \mu_k\) of (3) is
where \( (A^k x)_{\#} \mu_0\) denotes the pushforward of \( \mu_0\) via the map \( f(x) = A^k x\) , and a similar definition holds for the other term after convolution. The steady-state distribution \( \mu_\textup{ss}\) for a fixed decision \( u\) is
2.3 Problem formulation
We aim to find a decision \( u\) that optimizes the steady-state behavior of the dynamic distribution (3):
(6)
where \( \mu_\textup{ss}(u)\) is the steady-state distribution of (3) induced by \( u\) , see also (4). Let the reduced objective function of problem (6) be denoted by
(7)
The decision-dependent problem (6) formalizes the steady state of the closed loop illustrated by (1) in (1.1). This problem is relevant in many scenarios with a vast population or intrinsic uncertainties, e.g., voting and recommender systems.
Problem (6) involves several major challenges in terms of the nonconvex objective and the unknown dynamics underlying the decision-dependent distribution.
- First, the distribution dynamics (3) induce the steady-state distribution \( \mu_\textup{ss}(u)\) and further bring about a composite structure in problem (6). Even for a convex function \( \Phi\) , since the steady-state map \( h(u,d)\) is nonlinear, the overall objective \( \tilde{\Phi}(u)\) can be nonconvex.
- Another challenge originates from the unknown distribution dynamics, which render the structure of decision dependence elusive and preclude an offline numerical scheme based on the exact (re)formulation of problem (6).
- Finally, we cannot directly sample from the steady state distribution \( \mu_\textup{ss}(u)\) unless we wait sufficiently long, because the distribution \( \mu_k\) is constantly changing with time \( k\) and eventually approaches \( \mu_\textup{ss}(u_k)\) .
To overcome the above challenges, we will propose an online stochastic algorithm in (3) that samples from the current distribution \( \mu_k\) and regulates the distribution shift by anticipating its sensitivity with respect to the decision.
We focus on steady-state performance due to relevance, generality, and tractability. First, in many problems an optimal steady state matters more than transients, with the latter often not even being modeled, see for instance in many case studies where feedback optimization or performative prediction is applied. This setup will also allow us to circumvent the need for model knowledge by exploiting distribution sensitivity, which is easier to learn. Second, if we analyze the behavior of a stable and dynamic distribution over a sufficiently long horizon, then the average performance metric (i.e., the cumulative objective values divided by the number of iterations) essentially converges to the steady-state objective. Finally, in this context we can go beyond the assumptions and policy classes considered in the mean-field literature [21] and establish provable guarantees for continuous decision vectors given a broad class of nonlinear dynamics and nonconvex objective functions. Specifically, we make the following assumptions on the objective.
Assumption 2
The objective \( \tilde{\Phi}(u)\) is well defined (i.e., \( \mathrm{ \mathbb{E} }_{d \sim \mu_d}[\Phi(u,h(u,d))] < \infty\) ), \( L_{\tilde{\Phi}}\) -smooth (with \( L_{\tilde{\Phi}}\) -Lipschitz gradients), and bounded below. The function \( \Phi(u,p)\) is \( L_\Phi^p\) -Lipschitz in \( p\) . The partial gradients \( \nabla_u \Phi(u,p)\) and \( \nabla_p \Phi(u,p)\) are \( M_\Phiû\) -Lipschitz and \( M_\Phi^p\) -Lipschitz in \( p\) , respectively.
(2) requires a well-defined expectation function, which is common in stochastic optimization [see 12, Section 9.2.5] and can be satisfied, e.g., when for each \( u\) , \( \Phi(u,h(u,d))\) is dominated by an integrable function of \( d\) . The smoothness condition is also standard [see 52] and holds, e.g., when for every stochastic sample \( p_\textup{ss}=h(u,d)\) , the objective \( \Phi(u,p_\textup{ss}) = \Phi(u,h(u,d))\) is \( L_{\tilde{\Phi}}\) -smooth and the second moment of \( L_{\tilde{\Phi}}\) is bounded. The requirement that the partial gradients are Lipschitz in the random variable \( p\) is related to (though not the same as) the joint smoothness property used in performative prediction [15, 27]. Moreover, the condition that \( \tilde{\Phi}(u)\) is bounded below implies that problem (6) admits a finite optimal value \( \tilde{\Phi}^* \in \mathbb{R}\) .
Assumption 3
There exists a positive random variable \( L(d)\) such that \( \mathbb{E}_{d \sim \mu_d}[L(d)] < \infty\) , and that for all \( u_1,u_2 \in \mathbb{R}^n\) , \( |\Phi(u_1,h(u_1,d)) - \Phi(u_2,h(u_2,d))| \leq L(d) \|u_1 - u_2\|\) .
(3) is similar to [12, Eq. (9.130)]. It is a sufficient condition for the interchangeability of the expectation and gradient operators, see [12, Theorem 9.56] and also (8) in (3.1) below. If the function \( \Phi(u,h(u,d))\) is Lipschitz continuous in \( u\) , then (3) holds naturally.
3 Online Stochastic Decision-Making
We present our online stochastic algorithm for solving the decision-dependent problem (6). The main challenges stem from the non-stationary and largely unknown distribution due to the dynamics (3) and the decisions \( (u_k)_{k\in \mathbb{N}_{+}}\) . To disentangle the complexity associated with distributions, we leverage samples drawn from the current transient distribution as informative characterizations and feedback. Motivated by the composite structure of the objective, we further enhance the algorithmic update with a term that proactively anticipates and shapes the dynamic distribution based on its sensitivity. Thus, we ensure local optimality of solutions even for nonconvex problems.
3.1 Intuition of the stochastic gradient
We provide the intuition of constructing appropriate stochastic gradients for online decision-making as per (6). Ideally, we aim to obtain the gradient of the objective \( \tilde{\Phi}\) at \( u_k\) , i.e.,
(8)
(9)
where (a.1) leverages interchangeability of the expectation and gradient operators thanks to (3), see also [12, Theorem 9.56]; (a.2) uses the law of the total derivative; (a.3) involves expectation with respect to the joint distribution \( \gamma_\textup{ss}(u_k) \triangleq (h(u_k,\cdot), \mathopen{}\mathrm{Id})_{\#} \mu_d\) of the steady-state variable \( p \sim \mu_\textup{ss}(u_k) = h(u_k,\cdot)_{\#} \mu_d\) and the exogenous input \( d \sim \mu_d\) .
However, the exact gradient \( \nabla \tilde{\Phi}(u_k)\) can be difficult to calculate for two reasons. First, it involves the expectation with respect to the random variable \( p\) , although in practice we can only access finite samples of the distribution. Second, since each sample needs a few iterations to approach its steady state, the steady-state distribution \( \mu_\textup{ss}(u_k)\) of \( p\) corresponding to the decision \( u_k\) is unavailable at the current time \( k\) .
To address these issues, we use samples drawn from the current distribution \( \gamma_k\) to construct a mini-batch stochastic gradient, thereby informing decision-making. The intuition is that \( \gamma_k\) , as reflected by these samples, serves as a reasonable proxy for the steady-state distribution \( \gamma_\textup{ss}(u_k)\) , provided that neighboring decisions (i.e., \( u_{k-1}\) and \( u_k\) ) are close and the iteration counter \( k\) is large. Consequently, the expected gradient involving \( \gamma_k\) also becomes a close approximation of the exact gradient \( \nabla \tilde{\Phi}(u_k)\) entailing \( \gamma_\textup{ss}(u_k)\) . We will formalize this intuition in (4.1).
3.2 Algorithmic design
Guided by the aforementioned intuition, our online stochastic algorithm for solving problem (6) is
(10)
where \( \eta > 0\) is a constant step size, \( k\) is the iteration counter, and \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) is a stochastic gradient based on mini-batches, i.e.,
(11)
In (11), \( n_\textup{{mb}} \in \mathbb{N}_{+}\) is the size of the mini-batch, and \( \nabla_u h(u_k,d^i)\) is the steady-state sensitivity of \( p^i_\textup{ss}\) with respect to the decision \( u_k\) . Such a sensitivity admits various simplifications and can often be learned from data in practice, see the discussion in (2.2). For instance, the sensitivity is a constant matrix given linear dynamics and does not involve \( d^i\) if the exogenous input is additive. Further, \( p_k^1, …, p_k^{n_\textup{{mb}}}\) are samples drawn from the transient distribution \( \mu_k\) at time \( k\) . These samples rely on the decisions owing to the dynamics (3), thereby causing a composite structure in the objective \( \Phi(u,p)\) .
In essence, the mini-batch stochastic gradient (11) is a finite-sample approximation of
(12)
i.e., the approximate expected gradient at \( u_k\) when \( p\) and \( d\) satisfy the joint distribution \( \gamma_k\) . Specifically, \( \gamma_k = (f^{(k)}(x,y),y)_{\#}\alpha(x,y)\) denotes the pushforward of \( \alpha\) in (3). Further, \( f^{(k)}(p_0,d)\) is the value of \( p_k\) given a pair of the initial state \( p_0\) and the exogenous input \( d\) sampled from the joint distribution \( \alpha\) , a sequence of decisions \( (u_i)_{i=1,…,k}\) , and the dynamics (3). That is, \( f^{(k)}: \mathbb{R}^m \times \mathbb{R}^r \to \mathbb{R}^m\) is a map parameterized by \( u_1,…,u_k\) . We define the special case \( f^{(0)}(p_0,d)\) as \( p_0\) . We will show in (4) that with suitable algorithmic parameters, \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) and \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) are close to \( \nabla \tilde{\Phi}(u_k)\) , enabling the stochastic algorithm (10) to yield (locally) optimal solutions.
The mini-batch stochastic gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) involves two terms. Term ➀ in (11) leverages the current sample \( p_k^i\) to construct a partial gradient with respect to \( u\) . Term ➁ in (11) anticipates how the decision \( u_k\) will influence the sample \( p\) (and in turn the objective) and uses this link for achieving optimality. As explained in (3.1), these two terms result from the aforementioned composite structure of \( \Phi(u,p)\) and the law of the total derivative. While the update rule (10) seems obvious from our presentation, most related online methods do not use an anticipating term as ➁ in (11), as discussed in (1.3).
3.3 Properties of the stochastic gradient
Let \( \mathcal{F}_k\) be the \( \sigma\) -algebra generated by the random variables \( \widehat{\nabla}_\textup{{mb}}^{0} \tilde{\Phi}(u_0), …, \widehat{\nabla}_\textup{{mb}}^{k}\tilde{\Phi}(u_k)\) . Hence, the decision \( u_k\) is measurable with respect to \( \mathcal{F}_{k-1}\) . We make the following assumption on the variance of the stochastic gradient constructed from an individual sample. For a stochastic vector \( \xi \in \mathbb{R}^n\) , we define its variance as \( \operatorname{Var} [\xi] \triangleq \mathrm{ \mathbb{E} }\left[\|\xi - \mathrm{ \mathbb{E} }[\xi]\|^2\right] = \mathrm{ \mathbb{E} }[\|\xi\|^2] - \left\|\mathrm{ \mathbb{E} }[\xi]\right\|^2\) .
Assumption 4
The stochastic gradient satisfies
where \( M, M_V \geq 0\) are constants.
(4) is a standard and relatively weak statement that the variance of the stochastic gradient is restricted [52]. It implies that this variance can be nonzero at the point where \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) equals zero and grows at most quadratically in the norm of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) .
Given the dynamics (3) and independent pairs \( (p_0^1,d^1), …, (p_0^{n_\textup{{mb}}},d^{n_\textup{{mb}}})\) of initial states and exogenous inputs, when conditioned on \( \mathcal{F}_{k-1}\) , the samples \( p_k^1, …, p_k^{n_\textup{{mb}}}\) collected at time \( k\) are still independent. Building on this observation, we specify some key properties of the mini-batch gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) in the lemma below.
Lemma 1
Given the dynamics (3) and independent sample pairs \( (p_0^1,d^1), …, (p_0^{n_\textup{{mb}}},d^{n_\textup{{mb}}})\) of initial states and exogenous inputs, \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) in (11) is an unbiased estimate of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) , i.e.,
(13)
Moreover, if (4) holds, then the expected second moment of \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) is bounded, i.e.,
(14)
4 Performance Analysis
We analyze the interplay between the distribution dynamics (3) and the proposed online stochastic algorithm (10). In (4.1), we characterize the distribution shift driven by the decision-maker through the Wasserstein metric. We then establish the optimality guarantees of the algorithm (10) when applied to the distribution dynamics (3). These guarantees hold in expectation and with high probability and are given in (4.2) and (4.3), respectively, thereby covering a broad spectrum of the overall performance. Finally, we consider a finite-sample regime and provide generalization certificates in (4.4).
4.1 Distribution shifts
The distribution dynamics (3) bring about constant shifts of the joint distribution \( \gamma_k\) . We characterize such distribution shifts through the lens of the Wasserstein distance. Specifically, we focus on the behavior of \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) , i.e., the Wasserstein distance between the joint distribution \( \gamma_k\) at time \( k\) and the joint steady-state distribution \( \gamma_\textup{ss}(u_k)\) induced by the decision \( u_k\) .
Throughout this section, we consider the space \( (\mathbb{R}^{m+r},c)\) endowed with the metric
(15)
where \( p,p' \in \mathbb{R}^m, d,d' \in \mathbb{R}^r\) , and \( \|\cdot\|_P\) is the weighted norm. Then, \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) is defined by
where \( (p,d)\) and \( (p',d')\) are distributed according to \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) , respectively.
The following lemma gives an upper bound on the Wasserstein distance \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) and establishes a related recursive inequality. It is built on the properties of the pushforward operation induced by Borel maps, see [58, Proposition 3]. Recall that \( L_f^p\) is the Lipschitz constant of the dynamics function \( f\) with respect to \( p\) under \( \|\cdot\|_P\) , and that \( L_hû\) is the Lipschitz constant of the steady-state map \( h\) of (3) with respect to \( u\) under \( \|\cdot\|\) , see (1) and the discussion below. Further, \( \lambda_{\max}(P) > 0\) is the maximum eigenvalue of the positive definite matrix \( P\) , and \( f^{(k)}(p_0,d)\) denotes the value of \( p_k\) given a pair \( (p_0,d) \sim \alpha\) and past decisions, see the paragraph below (12) in (3.1).
Lemma 2
Let (1) hold. With (3), the joint distributions \( (\gamma_k)_{k\in \mathbb{N}}\) satisfy
(16.a)
(16.b)
Moreover, for any \( u_0 \in \mathbb{R}^n\) , \( V_0 \triangleq \int_{\mathbb{R}^m \times \mathbb{R}^r} \|f^{(0)}(p_0,d) - h(u_0,d)\|_P \,\mathrm{d} \alpha(p_0,d)\) is finite.
(2) characterizes the behavior of \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) through the evolution of the upper bound \( V_k\) . Specifically, this upper bound exhibits perturbed contraction (16.b), where the contraction coefficient is \( L_fû \in (0,1)\) , and the perturbation term is proportional to the difference of consecutive inputs. If the inputs are kept fixed (i.e., \( u_k = u,\forall k \in \mathbb{N}\) ), then \( V_k\) and hence \( W_1(\gamma_k,\gamma_\textup{ss}(u))\) converge to \( 0\) as \( k\) increases. The implication is that \( \gamma_k\) converges weakly in \( \mathcal{P}_1(\mathbb{R}^m)\) to the steady-state distribution \( \gamma_\textup{ss}(u)\) , see [5, Theorem 6.9].
We quantify the cumulative sum of squared Wasserstein distances in the theorem below by building on (2). As explained in (3.1), the difference between \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) causes a bias in the gradient at time \( k\) . Such a cumulative sum reflects how those biases accumulate when we deploy our online algorithm (10) and will be useful for quantifying the convergence measure of the nonconvex problem, see (2) in (4.2) and (4) in (4.3).
Theorem 1
Given (1) and the distribution dynamics (3), the joint distributions \( (\gamma_k)_{k\in \mathbb{N}}\) satisfy
(17)
where the coefficients are \( \rho_1 = \frac{1+(L_f^p)^2}{2} \in (0,1)\) and \( \rho_2 = \frac{1+(L_f^p)^2}{1-(L_f^p)^2} (L_f^p L_hû)^2 \lambda_{\max}(P)\) . Furthermore, the online stochastic algorithm (10) applied to (3) ensures that
(18)
Analogous to (16.b), the upper bound on the sum of squared Wasserstein distances depends on the cumulative variation in decisions. After invoking the gradient-based update rule (10), we know that this cumulative variation is proportional to the step size \( \eta\) and the squared norm of the mini-batch gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) , where \( k=0,…,T-\!2\) . In the following subsections, we will exploit (18) and the connection between \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) and \( \nabla \tilde{\Phi}(u_k)\) to establish convergence guarantees.
An important implication of the distribution shift due to the dynamics (3) is that the mini-batch stochastic gradient (11), albeit unbiased with respect to the approximate gradient \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) (see (12)), is a biased estimate of the true gradient \( \nabla \tilde{\Phi}(u_k)\) . The reason is that we draw samples from the current distribution \( \gamma_k\) instead of the steady-state distribution \( \gamma_\textup{ss}(u_k)\) to construct (11). Let \( e_k\) denote the difference of expected gradients due to the discrepancy between \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) , that is,
(19)
(20)
The following lemma provides an upper bound on \( \|e_k\|\) through \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) , i.e., the Wasserstein distance between two joint distributions \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) .
Lemma 3
If (1,2,3) are satisfied, then
(21)
where \( L = \max\left(L_{\Phi}^p M_h^d, \frac{M_\Phiû + L_hû M_\Phi^p}{\sqrt{\lambda_{\min}(P)}} \right)\) .
(3) indicates that the difference \( e_k\) between the approximate gradient \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) involving \( \gamma_k\) and the true gradient \( \nabla \tilde{\Phi}(u_k)\) involving \( \gamma_\textup{ss}(u_k)\) is proportional to the Wasserstein distance \( W_1(\gamma_k, \gamma_\textup{ss}(u_k))\) . By referring to (2) on the evolution of \( W_1(\gamma_k, \gamma_\textup{ss}(u_k))\) , we know that when neighboring decisions (i.e., \( u_k\) and \( u_{k-1}\) ) are close and the iteration counter is large, \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) is a close approximation of \( \nabla \tilde{\Phi}(u_k)\) . This aligns with the intuition stated at the end of (3.1).
4.2 Optimality in expectation
We present the optimality guarantee of our stochastic algorithm (10) when applied to the distribution dynamics (3). The major challenge is that the evolution of the distribution and the iterates of the algorithm are coupled. To disentangle this coupling, we leverage the characterizations of the distribution shift in (1) and the descent-type iterate (10) and then quantify the overall convergence measure, i.e., the average expected second moment of gradients.
Recall that \( \tilde{\Phi}(u) = \mathrm{ \mathbb{E} }_{p \sim \mu_\textup{ss}(u)}[\Phi(u,p)]\) is the objective, \( \tilde{\Phi}^*\) is the optimal value of problem (6), \( \nabla \tilde{\Phi}(u)\) is given by (8), \( \eta\) is the step size, \( T \in \mathbb{N}_+\) is the number of iterations, \( n_\textup{{mb}} \in \mathbb{N}_+\) is the size of the mini-batch, \( L\) is the constant specified in (3), \( M\) is the constant in the variance bound in (4), and \( \rho_1\) and \( \rho_2\) are constants given in (1). In the following theorem, we provide the first main convergence result of our stochastic algorithm (10).
Theorem 2
Suppose that (1,2,3,4) hold. Let \( \eta\) be chosen such that
(22)
The stochastic algorithm (10) applied to the distribution dynamics (3) guarantees that
(23)
By choosing \( \eta\) as the upper bound in (22), the order of the right-hand side of (23) is
(24)
The convergence measure analyzed in (2) is the average of the expected second moments of \( \nabla \tilde{\Phi}(u_k)\) . The expectation is taken with respect to the randomness of the proposed algorithm, i.e., the randomness in selecting mini-batch samples. This measure is typical in nonconvex optimization to characterize (local) optimality of solutions [52]. The upper bound (23) on this measure involves the number of iterations \( T\) , the step size \( \eta\) , and other constants related to the problem and the algorithm. With a step size attaining the upper bound in (22), our stochastic algorithm (10) yields an \( \mathcal{O}(1/\sqrt{T})\) rate of convergence, matching stochastic gradient descent for static nonconvex problems. It is common in the stochastic optimization literature [53, 52] to let the bound on the step size be a function of the number of iterations, facilitating the analysis of the convergence rate.
The rate (24), nonetheless, is nontrivial given the presence of unknown dynamics and the composite structure of the decision-dependent problem. Online stochastic algorithms reviewed in (1.3) that lack an anticipation term as (11) can incur persistent biases in gradients, causing sub-optimality (namely, the average expected second moment of gradients does not vanish). Although dynamics inhibit us from directly accessing steady-state samples and cause biases in gradients, we demonstrate that the accumulation of these biases does not deteriorate the overall convergence rate. This is largely due to the contracting distribution dynamics and a relatively slow algorithm (with a bounded step size), à la time-scale separation [24] as quantified by (22). Finally, we remark that variance reduction techniques offer a promising means of improving the convergence rate [52].
The expected gradient \( \nabla \tilde{\Phi}(u_k)\) , as part of the convergence measure in (23), involves the steady-state distribution \( \gamma_\textup{ss}(u_k)\) . In practice, however, we can only sample from the current distribution \( \gamma_k\) to gain an understanding of the quality of solutions. In the following corollary, we analyze the average expected second moment of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) involving \( \gamma_k\) , see (12).
Corollary 1
Let the conditions of (2) hold. The stochastic algorithm (10) acting on the distribution dynamics (3) ensures that
(25)
(1) implies that the average expected second moments of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) related to the current distribution \( \gamma_k\) are still of the order of \( \mathcal{O}(1/\sqrt{T})\) . The reason is that the convergence measures in (24) and (25) can be connected via the average expected squared Wasserstein distance, i.e., \( \big(\sum_{k=0}^{T-1} \mathrm{ \mathbb{E} }\left[W_1(\gamma_k,\gamma_\textup{ss}(u_k))^2\right]\big)/T\) , whose order is the same as both measures, see also (60) in (D.1).
Apart from the above optimality guarantees, we are also interested in the convergence of the distribution dynamics (3) while interacting with the decision-maker as per (10). We provide the convergence guarantee in the following theorem.
Theorem 3
Let the conditions of (2) hold. Then,
(26)
In (3), we characterize the convergence of the distribution dynamics (3) via the average expected Wasserstein distance between the current distribution \( \gamma_k\) and the corresponding steady-state distribution \( \gamma_\textup{ss}(u_k)\) . Similar to (23), the upper bound in (26) also depends on the number of iterations, the step size, and other problem and algorithm specific constants. As the number of iterations grows, the average expected Wasserstein distance becomes closer to zero, implying that the dynamic distribution approaches the steady-state distribution in the long run. This convergence plays an important role in optimality certificates that couple the distribution dynamics (3) and the algorithm (10), see the discussions below (1,2).
We remark that the Wasserstein metric for the distribution dynamics (3) in (3) is of the same order as the average expected gradient norm \( \sum_{k=0}^{T-1} \mathbb{E}[\|\nabla \tilde{\Phi}(u_k)\|]/T\) rather than the average expected second moment of gradients in (2). Given the analogy between optimization and sampling, readers may wonder why the convergence rate (26) does not match the \( \mathcal{O}(1/\sqrt{T})\) rate of Langevin dynamics for sampling from a target distribution [see, e.g., 54]. Apart from the distinction in problem setups, another major reason for this difference in convergence rates lies in the coupling of the distribution dynamics (3) and the algorithm (10). As characterized by (18), the incurred cumulative Wasserstein distance is related to the second moments of gradients. Since the nonconvex objective of problem (6) limits the achievable order of the average second moment (namely, \( \mathcal{O}(1/\sqrt{T})\) , see (2)), the order of the average Wasserstein distance between distributions is also restricted.
4.3 Optimality with high probability
The convergence guarantee in (2) holds in expectation. It reflects the average performance pertaining to the interplay between the stochastic algorithm (10) and the distribution dynamics (3). However, some cases (e.g., with constraints on computational resources or time) allow only a single trial or a few trials of the stochastic algorithm, rendering the occurrence of an extreme outcome a key concern, particularly in high-stakes scenarios, such as elections motivated in (1). In this regard, another angle for characterizing algorithmic and distributional behaviors is convergence with high probability. Our goal is to quantify the confidence level that a stochastic algorithm yields satisfactory solutions when applied to distribution dynamics after a single trial involving many iterations.
To establish high-probability guarantees, we need an assumption that differs from (4) and is instead related to the distribution of the gradient noise. Recall from (13) in (1) that the mini-batch gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) is an unbiased estimate of the approximate gradient \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) . Let
(27)
be the noise in \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) relative to \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) . Hence, \( \mathrm{ \mathbb{E} }\left[\xi_k | \mathcal{F}_{k-1}\right] = 0\) , where \( \mathcal{F}_{k-1}\) is the \( \sigma\) -algebra generated by \( \widehat{\nabla}_\textup{{mb}}^{0} \tilde{\Phi}(u_0),…,\widehat{\nabla}_\textup{{mb}}^{k-1} \tilde{\Phi}(u_{k-1})\) . Specifically, we assume that \( \xi_k\) is sub-Gaussian, i.e., with a tail dominated by the tail of a Gaussian distribution. This specification is formalized by the following assumption.
Assumption 5
When conditioned on \( \mathcal{F}_{k-1}\) , the noise \( \xi_k\) (27) is sub-Gaussian, i.e., there exists \( \sigma_\textup{{mb}} > 0\) such that for any \( u_k \in \mathbb{R}^n\) ,
(28)
Compared to (4) on the variance, (5) specifies that the gradient noise \( \xi_k\) is light-tailed. Building on Jensen’s inequality (i.e., \( \forall X \in \mathbb{R}, \exp(\mathrm{ \mathbb{E} }[X]) \leq \mathrm{ \mathbb{E} }[\exp(X)]\) ), (5) implies that the variance of \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) admits a constant upper bound \( \sigma_\textup{{mb}}^2\) , which is a bit stronger than (4). In practice, (5) can be satisfied when the noise in the sample gradient corresponding to each individual is sub-Gaussian, or when the mini-batch size \( n_\textup{{mb}}\) is large enough so that the central limit theorem ensures that \( \xi_k\) is close to Gaussian. Such light-tailed sub-Gaussian noises are considered in [6, 7] to analyze the behaviors of stochastic gradient descent for static problems. Further, self-normalized concentration inequalities provide a promising avenue for handling heavy-tailed (e.g., sub-Weibull) noises, see [8, 9].
We establish the high-probability guarantee of our stochastic algorithm (10) when applied to the distribution dynamics (3). The involved variables, parameters, and constants are the same as those in (2). The proof leverages the characterization of the cumulative squared Wasserstein distances in (1) and some high-probability bounds on terms involving \( \xi_k\) .
Theorem 4
Suppose that (1,2,3,5) hold. Let \( \eta\) be chosen such that
(29)
The stochastic algorithm (10) applied to the distribution dynamics (3) guarantees that for any fixed \( \tau \in (0,1)\) , with probability at least \( 1-\tau\) ,
(30)
By selecting \( \eta\) as the upper bound in (29), the order of the right-hand side of (30) is
The upper bound on the step size in (29) is of the same order as that of (22) in (2), although constant coefficients differ. In the stochastic optimization literature [53, 52], this bound is typically set as a function of the number of iterations to characterize the convergence rate. The convergence measure in (4) is still the average second moment of gradients. In contrast to (2), however, the measure here does not involve expectation anymore. The upper bound (30) scales inversely with the square root of the number of iterations \( T\) . Moreover, it features a logarithmic dependence on the inverse of the failure probability \( \tau\) . This dependence is favorable particularly when the desired confidence level is high, i.e., when \( \tau\) is small. For example, \( \tau=10^{-4}\) leads to \( \ln \frac{1}{\tau} = 4\) , which translates to a moderate increase in magnitude. Hence, under the appropriate (5), similar convergence results as (2) also hold with high probability.
Analogous to (3), we offer a high-probability characterization of the convergence of the distribution dynamics (3) when driven by a decision-maker as per (10).
Theorem 5
Let the conditions of (4) hold. For any fixed \( \tau \in (0,1)\) , with probability at least \( 1-\tau\) ,
(31)
By choosing \( \eta\) as the upper bound in (29), the order of the right-hand side of (31) is
(5) ensures that with high probability, the average Wasserstein distance between the current distribution and the associated steady-state distribution approaches zero at a rate of \( \mathcal{O}(1/T^{\frac{1}{4}})\) as the number of iterations \( T\) increases. Moreover, the upper bound on this average distance exhibits a polylogarithmic dependence on the inverse of the failure probability \( \tau\) . Overall, the distributions \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) are close on average with high probability.
4.4 Generalization in a finite-sample regime
In this subsection, we examine a finite-sample regime, where access is limited to a specific set of samples rather than allowing unrestricted sampling from the full distribution as in problem (6). When applied in this context, the stochastic algorithm (10) yields decisions that essentially optimize an empirical objective associated with these samples. We are interested in the generalization guarantees on how such decisions perform in the problem involving the overall distribution.
This setup is of interest from an application perspective. Various reasons, e.g., the strategy of seeding trials or the restricted sampling due to privacy concerns, may cause us to only work with specific samples from the distribution. Yet, we hope the decisions obtained from analyzing these finite samples can generalize to the distribution-level problem. We will show how our distributional perspective allows seamless integration of the measure concentration argument [55] into performance analysis, thus facilitating generalization guarantees.
The distributions of the initial state and the exogenous input are \( \mu_0\) and \( \mu_d\) , respectively. Moreover, let \( p^1_0, …, p^N_0 \sim \mu_0\) and \( d^1, …, d^N \sim \mu_d\) be independent and identically distributed samples drawn from these distributions, where \( N \in \mathbb{N}_{+}\) is the total number of samples. The empirical distributions of the initial state and the exogenous input are \( \mu^N_0 = \frac{1}{N} \sum_{i=1}^{N} \delta_{p^i_0}\) and \( \mu^N_d = \frac{1}{N} \sum_{i=1}^{N} \delta_{d^i}\) , respectively. At every time \( k\) , the decision affects the overall distribution \( \mu_k\) as per (3) and in turn influences the resulting empirical distribution \( \mu^N_k\) . In a finite-sample regime, the empirical distribution \( \mu^N_k\) rather than the full distribution \( \mu_k\) is accessible for sampling. For this setting, the online stochastic algorithm (10) generates decisions \( \{u_0^N,…,u_{T-1}^N\}\) that solve the following finite-sample empirical problem
(32)
Our focus is on establishing generalization guarantees on the performance of the decisions \( \{u_0^N,…, u_{T-1}^N\}\) in the distribution-level problem (6).
(2) allows us to characterize the stationarity of decisions concerned with the empirical objective \( \tilde{\Phi}^N\) in (32). In terms of the distribution-level performance, however, we center on the stationarity in the sense of \( \tilde{\Phi}\) in (7), i.e., the reduced objective of problem (6). To this end, we leverage the following decomposition
(33)
The left-hand side of (33) is the squared norm of the gradient \( \nabla \tilde{\Phi}(u_k^N)\) , which reflects the quality of decisions for the distribution-level problem (6). Term ➀ in (33) is the squared norm of the difference between the empirical gradient \( \nabla \tilde{\Phi}^N\) and the gradient \( \nabla \tilde{\Phi}\) , and it represents the generalization error [9]. Term ➁ in (33) is the squared norm of the empirical gradient, constituting the optimization error for the empirical problem (32).
The following lemma gives a high-probability bound on the generalization error averaged over iterations. It is built on the measure concentration result derived in Wasserstein distances, see [55, Theorem 2]. Recall that \( r\) is the size of the exogenous input \( d\) .
Lemma 4
Let (1,2,3) hold. Suppose that there exist \( \theta > 1\) and \( \kappa > 0\) such that \( \mathcal{E}_{\theta,\kappa}(\mu_d) \triangleq \int_{\mathbb{R}^r} e^{\kappa |x|^\theta} \,\mathrm{d} \mu_d(x)\) is finite. For any fixed \( \tau \in (0,1)\) , with probability at least \( 1 - \frac{\tau}{2}\) , the decisions \( \{u_0^N, …, u_{T-1}^N\}\) satisfy
where \( c_1\) and \( c_2\) are positive constants that only depend on \( r,\theta,\kappa\) , and \( \mathcal{E}_{\theta,\kappa}(\mu_d)\) .
The finite moment condition (namely, on \( \mathcal{E}_{\theta,\kappa}(\mu_d)\) ) in (4) specifies the degree to which the distribution \( \mu_d\) is light-tailed. This condition is common in the literature [55, 26]. (4) encompass both the low-data and high-data regimes.
We now characterize the generalization performance of our stochastic algorithm (10). We focus on the decisions \( \{u_0^N,…,u_{T-1}^N\}\) obtained by the algorithm (10) in solving the finite-sample problem (32), with the mini-batch size \( n_\textup{{mb}}\) satisfying \( 1 \leq n_\textup{{mb}} \leq N\) . The quality of these decisions is evaluated by the average second moment of gradients of the objective \( \tilde{\Phi}\) , which involves the distributions \( \mu_0\) and \( \mu_d\) and is associated with problem (6). Note that \( r\) is the size of \( d\) , \( \theta > 1\) is a constant present in \( \mathcal{E}_{\theta,\kappa}(\mu_d)\) , and \( c_1\) and \( c_2\) are constants specified in (4).
Theorem 6
Let (1,2,3,4) and the conditions of (4) hold. Consider the use of the stochastic algorithm (10) to solve the finite-sample problem (32), with the step size chosen by (29). Let \( \tau \in (0,1)\) be fixed. When \( N \geq \frac{1}{c_2} \ln\left(\frac{2c_1}{\tau} \right)\) , with probability at least \( 1-\tau\) ,
and the overall order is
When \( 1 \leq N < \frac{1}{c_2} \ln\left(\frac{2c_1}{\tau} \right)\) , with probability at least \( 1-\tau\) ,
(6) quantifies how the performance measure (i.e., the average second moment of the gradient \( \nabla \tilde{\Phi}(u_k^N)\) ) scales polynomially with the number of samples \( N\) and the number of iterations \( T\) , as well as polylogarithmically with the inverse of the specified failure probability \( \tau\) . As \( N\) and \( T\) increase, this performance measure approaches zero. It implies that the decisions \( \{u_0^N,…,u_{T-1}^N\}\) arising from the finite-sample problem (32) generalize to the distribution-level problem (6).
5 Case Studies
We present two case studies to demonstrate how decision dependence in stochastic optimization can be effectively addressed with our algorithm. The first case study delineates (1) in opinion dynamics and involves continuous population distributions. The second example originates from a recommender system context and focuses on discrete distributions over the probability simplex. Our code is publicly available .
5.1 Affinity maximization in a polarized population
We revisit (1) and consider the interaction of an opportunistic party and a polarized dynamic population. While the case study is streamlined, a relevant real-world example is the U.S. presidential election [22]. The ideological position of a party causes a shift in the position of each individual in the population. This party focuses on picking an ideology to gain the most votes. A tractable proxy for this goal is to maximize the steady-state population-wide affinities.
The shift of the individual position is described by the following polarized dynamics model adapted from [10, 11]
(34)
where \( p_k \in \mathbb{R}^m\) is the position of an individual at time \( k\) , \( q \in \mathbb{R}^m\) is the ideological position of the party, \( \lambda \in [0,1]\) is a coefficient for blending the current and initial positions, \( \sigma > 0\) regulates the position evolution, and \( \mu_0\) is the distribution of initial positions. In (34), the term \( (1-\lambda)p_0\) captures the persistent influence of the initial position \( p_0\) , which is also present in the classical linear Friedkin-Johnsen model [20]. The closer \( \lambda\) is to \( 1\) , the more an individual sticks to her initial position. Thanks to the normalization step, the position \( p_k\) is of unit norm. The coefficients \( \lambda\) and \( \sigma\) are the same for each individual, and therefore the overall population is homogeneous.
The polarized dynamics (34) feature biased assimilation [23]. If a specific individual prefers an ideology \( q\) (i.e., \( p_k^{\top} q > 0\) ), then her position will move closer to \( q\) . Conversely, if the ideology is disliked (i.e., \( p_k^{\top} q < 0\) ), then her position will instead move away from \( q\) , or more specifically, closer to \( -q\) . As illustrated in (2), the polarized dynamics (34) admit a steady-state position \( p_\textup{ss} = h(q,p_0)\) , and the location of \( p_\textup{ss}\) relative to \( q\) depends on the angle between \( p^0\) and \( q\) and the coefficients \( \lambda\) and \( \sigma\) . The affinity of an individual towards an ideology \( q\) at time \( k\) is given by the inner product \( p_k^{\top} q\) . We formalize the properties of the polarized dynamics (34) in the following theorem.
Theorem 7
For a fixed ideology \( q\) , the dynamics (34) admit a unique steady state \( p_\textup{ss}\) such that \( \tilde{p}_\textup{ss} = \lambda p_\textup{ss} + (1-\lambda)p_0 + \sigma \cdot (p_\textup{ss}^\top q) q, p_\textup{ss} = \tilde{p}_\textup{ss}/\|\tilde{p}_\textup{ss}\|\) . As \( \lambda \in [0,1]\) and \( \sigma > 0\) increase, \( p_\textup{ss}\) becomes closer to \( q\) (meaning \( p_\textup{ss}^\top q > p_0^\top q\) ) when \( p_0^\top q > 0\) , and to \( -q\) (meaning \( p_\textup{ss}^\top q < p_0^\top q\) ) when \( p_0^\top q < 0\) , indicating a stronger steering ability. The steady-state sensitivity \( \nabla_q h(q,p_0)\) is
(35)


(\( p_0^{\top} q > 0\) )

(\( p_0^{\top} q < 0\) )
To align with the majority and gain the most votes, the party aims to find an ideology \( q\) that optimizes the steady-state population-wide affinities:
(36)
where \( \mu_\textup{ss}(q)\) is the steady-state distribution induced by \( q\) , and the randomness is due to the persistent influence of the stochastic initial position acting as an exogenous input \( d\) in (3). In (36), the norm constraint on \( q\) represents restrictions (e.g., of resources or social norms) and ensures that the optimal solution to (36) is bounded.
As established in [23, Proposition 1], when \( \lambda = 1\) (i.e., the initial position disappears from (34)), then for a constant ideology \( q\) , \( p_\textup{ss} = q\) if \( p_0^{\top} q > 0\) , and \( p_\textup{ss} = -q\) if \( p_0^{\top} q < 0\) . In this case, the goal of individual affinity maximization is trivial: the key is to identify the hemisphere of \( p_0\) and then stick to some \( q\) that ensures \( p_0^{\top} q > 0\) [23]. Then, the maximum achievable affinity equals \( 1\) . However, for the general case that involves \( \lambda \in [0,1)\) and unknown \( p_0\) and extends from the individual to the population, affinity maximization is not straightforward anymore, and a systematic means of searching for \( q\) is required.
Problem (36) entails the underlying distribution dynamics (34). In practice, the difficulty of accessing an accurate dynamics model and the need for real-time decision-making can render the steady-state distribution \( \mu_\textup{ss}(q)\) elusive, thereby inhibiting offline numerical pipelines that rely on the formula or samples of \( \mu_\textup{ss}(q)\) . One online strategy to solve problem (36) is applying a stochastic algorithm in the style of performative prediction [16], see the discussions in (1.3). This algorithm exploits repeated sampling and retraining but is unaware of the composite structure wherein the steady-state distribution of positions depends on the ideology. The update rule of such a vanilla online algorithm is
(37)
where \( \mathrm{Proj}_{\|q\| \leq 1}(\cdot)\) denotes the projection onto the norm ball \( \{q \in \mathbb{R}^m \,|\, \|q\| \leq 1\}\) . This form of projected gradient ascent is due to maximization in (36). For comparison, we leverage the proposed online stochastic algorithm (10) interacting with the distribution dynamics (34) with the following adjustments. First, we add a projection step within iterations to satisfy the norm constraint \( \|q\| \leq 1\) . Second, we use real-time samples to construct in an online manner the sensitivity \( \widehat{H}(q_k,p_k)\) of the dynamics (34), namely,
(38)
where \( \tilde{p}_k = \lambda p_k + (1-\lambda) p_0 + \sigma \cdot (p_k^{\top} q_k) q_k\) . The difference of (38) compared to (35) lies in the replacement of \( p_\textup{ss}\) with the current position \( p_k\) . Overall, our online stochastic algorithm (10) tailored to (36) reads
(39)
Here the ascent-based update corresponds to maximization in (36).


In experiments, we set \( p_k\) and \( q\) to be \( 20\) -dimensional vectors, i.e., \( m=20\) . We generate a population of \( 1000\) individuals and sample their initial positions from a unit hemisphere in the \( 20\) -dimensional space, i.e., the set of unit vectors that form an angle not more than \( 90^{\circ}\) with a randomly generated reference vector. Regarding the parameters in the distribution dynamics (34) and the stochastic algorithms (37) and (39), we set the coefficients \( \lambda = 0.4\) , \( \sigma = 0.5\) , the step size \( \eta = 5 \times 10^{-3}\) , and the mini-batch size \( n_\textup{{mb}} = 50\) . As a benchmark, we use the optimizer IPOPT [56] to calculate a (locally) optimal solution \( q^*\) and the corresponding optimal value related to problem (36). This optimizer starts from a random initial guess and accesses all the parameters and data across the population. In practice, however, such full access can be prohibitive, and our online algorithm (39) is more desirable. We run \( 20\) independent trials of the online stochastic algorithms (37) and (39).
(6) illustrates the evolution of average affinities across the population when different algorithms interact with the dynamics (34) and solve problem (36). While using the same step size, our algorithm (39) exhibits a faster convergence rate, achieves a lower optimality gap, and attains a smaller distance to the optimal solution compared to the vanilla algorithm (37). The key reason stems from the algorithmic structure. The vanilla algorithm (37) is oblivious to the composite characteristic of problem (36) and solely focuses on adaptation. In contrast, our algorithm (39) takes into account the composite problem structure and actively regulates the shift of distribution dynamics (34), thereby attaining more favorable optimality guarantees. We remark that the non-vanishing errors in (6) are due to the variance of the stochastic sample collected during iterations. Further experiments confirm that a larger mini-batch size \( n_\textup{{mb}}\) and a smaller (or diminishing) step size \( \eta\) contribute to a lower asymptotic value of the convergence measure.
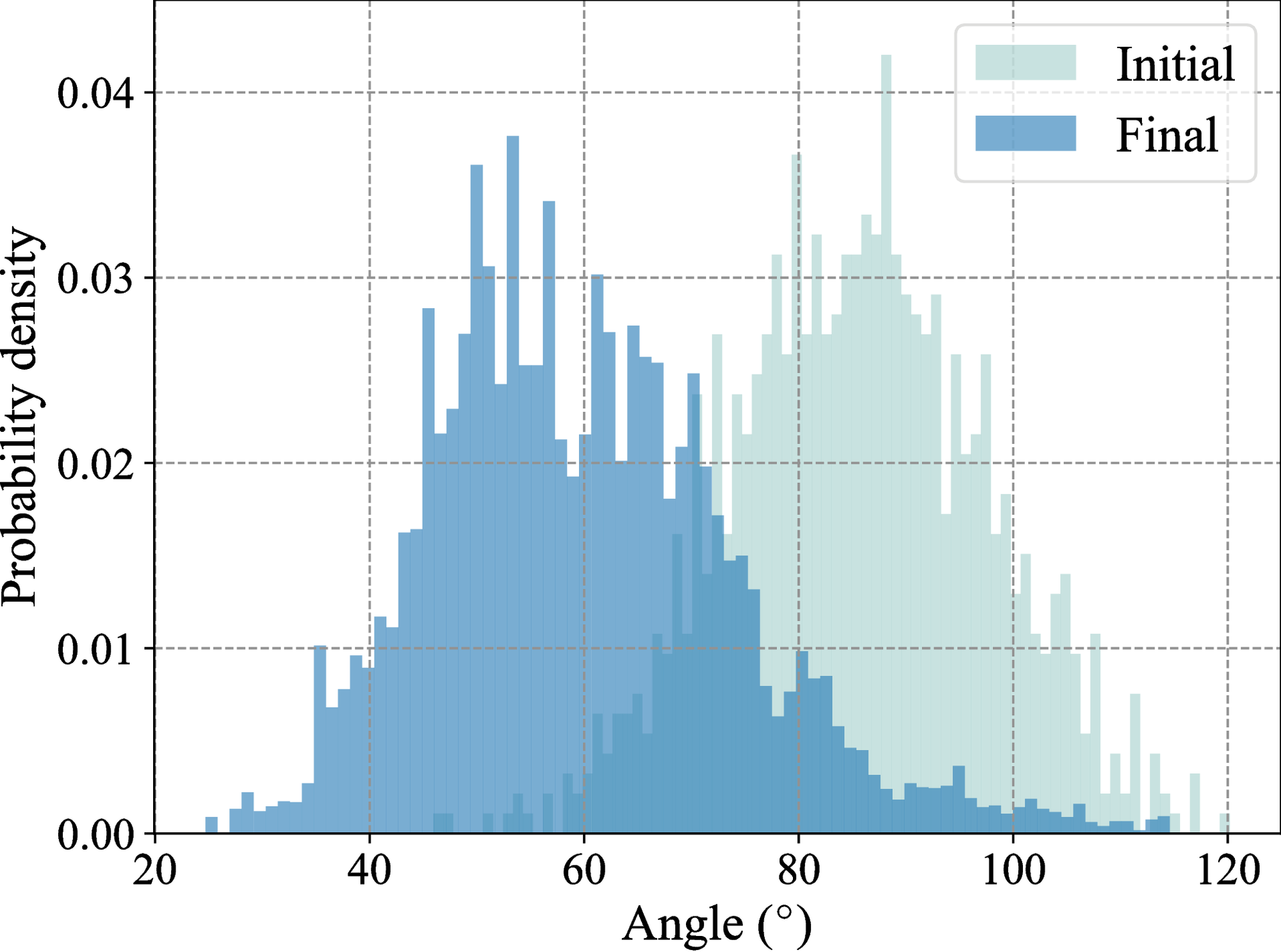


The above convergence behaviors are also linked with the histograms of the angles between the position and the decision across the population, see (9). Since the objective function of (36) is an inner product of the position \( p\) and the decision \( q\) , the angle between \( p\) and \( q\) is a useful indicator of the sign and the value of the inner product \( p^\top q\) . As shown in (9), the initial angles are largely distributed in \( [80^\circ, 100^\circ]\) , rendering the average population-wide affinity close to zero. The optimal solution returned by IPOPT and the solutions obtained by the vanilla algorithm (37) and our algorithm (39) all result in a final configuration wherein most angles fall into \( [40^\circ, 80^\circ]\) . Hence, the final average affinity is positive. Since the vanilla algorithm (37) focuses less on steering the distribution, in (10), there are relatively more final angles in \( [90^{\circ}, 115^{\circ}]\) , which accounts for a smaller affinity and a larger optimality gap as shown in (6). In contrast, the solution found by our algorithm (39) induces a nearly identical population-wide behavior as the ground truth.
5.2 Performance optimization given discrete choice distributions
(5.1) is concerned with affinity maximization involving continuous population distributions. In contrast, we now consider decision-making given discrete distributions lying in the probability simplex \( \Delta^{m} = \{p \in \mathbb{R}^m | 1^\top p = 1, 0 \leq p^i \leq 1, i=1,…,m\}\) , where \( m \in \mathbb{N}_{+}\) . This setting is motivated by a recommender system scenario, where a user selects a specific item (e.g., product, movie, or plan) from a set of candidates, and the choice model is characterized by a discrete distribution in \( \Delta^m\) . The recommender aims to optimize certain performance measures (e.g., of gain and diversity) by interacting with this user and adjusting its decision. This setting is also related to the multi-armed bandit problem, in that the user action described by a choice distribution \( p \in \Delta^m\) incurs performance feedback determined by the decision-maker.
We consider the following distribution dynamics
(40)
where \( p_k \in \Delta^m\) denotes the choice distribution at time \( k\) , \( q \in \mathbb{R}^m\) is a decision vector whose element represents, e.g., the price or loss of each item in a set, \( \lambda_1, \lambda_2 \in [0,1)\) are combination coefficients, and the \( i\) -th element of \( \operatorname{softmax}(-\epsilon q)\) is given by \( \exp(-\epsilon q^i)/\sum_{i=1}^{m} \exp(-\epsilon q^i)\) , where \( \epsilon > 0\) is a coefficient, and \( i=1,…,m\) . The term \( \operatorname{softmax}(-\epsilon q)\) gives a distribution consisting of probabilities proportional to the exponentials of \( -\epsilon q\) . One interpretation of this softmax operation is that an item \( i\) entailing a low price \( q^i\) is selected with a high probability. Similar to (34), the last term of (40) captures the persistent influence of the initial choice distribution. The steady-state distribution of (40) given a fixed decision \( q\) is
(41)
The recommender pursues maximizing its expected gain while preserving diversity, subject to certain budget requirements. This is formalized by the following problem
(42)
In problem (42), the first term \( p^\top q\) of the objective function represents the expected value given the steady-state discrete distribution \( p=h(q,p_0)\) , see also (41). This term indicates the expected price paid by the user, or conversely, the expected gain of the recommender. The second term of the objective is an entropy regularization with the coefficient \( \rho > 0\) , and its purpose is to promote diversity by favoring the distribution \( p\) with a high entropy. The remaining constraints of problem (42) specify budget requirements of the decision \( q\) , where \( b, \overline{q} > 0\) are constants.
Problem (42) involves the underlying distribution dynamics (40). An offline numerical solver hinges on an explicit and accurate model of (40) and requires sufficient waiting time for \( p_k\) to converge to its steady state \( p_\textup{ss}\) , which can be restrictive in practice. To solve problem (42) in an online fashion, the vanilla algorithm, which is of the style of performative prediction [16] and is oblivious to the composite problem structure, reads as follows
(43)
where \( \mathrm{Proj}_{\mathcal{C}}(\cdot)\) denotes the projection to the simplex \( \mathcal{C} = \{q \in \mathbb{R}^m | 1^\top q = b, 0 \leq q_i \leq \overline{q}\}\) , and \( \eta > 0\) is the step size. Another choice is the following derivative-free algorithm [57]
(44)
where \( \eta > 0\) is the step size, \( m\) is the dimension of \( q_k\) , \( \delta > 0\) is the smoothing parameter, \( v_k,v_{k-1}\) are independent random vectors uniformly sampled from the unit sphere in \( \mathbb{R}^m\) , and \( \Phi(q_k + \delta v_k, p_k)\) is the objective value evaluated at time \( k\) . Algorithm (44) exploits bandit feedback of the objective, and a similar version of (44) is adopted in [29, 41]. In contrast, our algorithm taking into account the composite structure due to decision dependence is
(45)
In (45), \( \eta>0\) is the step size, and the distribution sensitivity \( H^k\) (independent of \( p_k\) and \( p_0\) ) is
where the vector \( z_k \in \mathbb{R}^m\) is given by \( \exp(-\epsilon q_k)\) , and \( \operatorname{diag}(z_k)\) denotes a diagonal matrix with \( z_k\) as its diagonal elements. The ascent-based updates in (43), (44), and (45) are due to maximization in (42). Since the recommender interacts directly with a single user and does not require multiple samples, the update (45) differs slightly from (10), although both are grounded in the same principle.
In experiments, the vectors \( p\) for the choice distribution and the decision \( q\) are \( 100\) -dimensional vectors, i.e., \( m=100\) . In terms of the distribution dynamics (40), we set \( \lambda_1 = 0.2, \lambda_2 = 0.5\) , and \( \epsilon = 0.5\) . In problem (42), we set the regularization coefficient \( \rho = 0.1\) , the budget \( b = 250\) , and the upper bound \( \overline{q} = 5\) . For both algorithms (43) and (45), we select the step size \( \eta = 0.5\) . For the algorithm (44), we set \( \eta=0.1, \delta=2\) and run \( 20\) independent trials. We use IPOPT [56] to calculate the optimal value and the optimal point of problem (42) in an offline manner as benchmarks. However, as discussed earlier, numerical solvers can be restrictive in practice when the dynamics model (40) is inaccurate and real-time decision-making is necessary.


(13) shows the convergence results of online algorithms (43), (44), and (45) while interacting with the dynamics (40) to solve problem (42). The vanilla algorithm (43) is online in nature, and therefore it adapts to the changing distribution (40), eventually reaching a fixed-point solution. However, this algorithm suffers from significant sub-optimality, because it neglects the composite problem structure where the steady-state distribution is a function of the decision. The derivative-free algorithm (44) converges slowly due to the stochasticity of gradient estimates. In contrast, our algorithm (45) respects the composite structure by leveraging distribution sensitivities and regulating the shift of the choice distribution. Consequently, it attains a significantly higher solution accuracy. We remark that compared to (6) in (5.1), the curves of algorithms (43) and (45) in (13) do not exhibit stochastic oscillations, because we no longer resort to samples of a population distribution for mini-batch gradients.
The aforementioned difference in solution quality also causes the discrepancy in the evolution of the Wasserstein distances \( W_1(p_k, p_\textup{ss}(q^*))\) between the dynamic choice distribution \( p_k\) and the steady-state distribution \( p_\textup{ss}(q^*)\) induced by the optimal decision \( q^*\) via IPOPT . (16) illustrates such a difference in \( W_1(p_k, p_\textup{ss}(q^*))\) . Overall, these distances converge, thanks to the stable distribution dynamics (40) and the convergence of the algorithms to fixed decisions. We note that the vanilla algorithm (43) and the derivative-free algorithm (44) bring about biased final choice distributions, whereas our algorithm (45) drives the distribution to asymptotically converge to \( p_\textup{ss}(q^*)\) corresponding to the optimal decision. As pointed out earlier, this major difference is due to our algorithmic structure, which explicitly addresses the composite problem characteristic resulting from decision dependence.

6 Conclusion
We formulated a decision-dependent stochastic optimization problem, where the dependence originates from the closed-loop interaction between a decision-maker and a dynamically evolving distribution. We presented an online stochastic algorithm that leverages samples from the dynamic distribution, takes into account the composite structure of the problem by anticipating the sensitivity of the distribution with respect to the decision, and shapes the overall distribution to inform optimal decision-making. We established the optimality guarantees of the proposed algorithm both in expectation and with high probability. Furthermore, we quantified the generalization performance in a finite-sample regime with an empirical distribution.
Future directions include but are not limited to i) addressing constraints related to the decision and the distribution (represented by, e.g., bounds on risk measures), ii) analyzing a game-theoretic scenario where multiple decision-makers interact with a dynamic distribution, and iii) developing model-free methods (through, e.g., derivative-free optimization) that bypass the need for sensitivity matrices of distribution dynamics. We hope this work sparks further advances at the intersection of machine learning, stochastic optimization, and nonlinear control.
Acknowledgments We thank the Max Planck ETH Center for Learning Systems, the Swiss National Science Foundation via NCCR Automation, and the German Research Foundation for their support. We acknowledge N. Lanzetti for useful insights and comments, particularly on (2), and thank G. De Pasquale, P. Grontas, L. Aolaritei, S. Li, X. He, and S. Hall for helpful discussions.
A Useful Lemmas
First, we present a lemma that establishes the upper and lower bounds of the weighted norm.
Lemma 5
Let \( x \in \mathbb{R}^m\) and \( P \in \mathbb{R}^{m\times m}\) be positive definite. Then,
(46)
Proof
For a positive definite matrix \( P\) , both \( \lambda_{\max}(P)I - P\) and \( P - \lambda_{\min}(P)I\) are positive semidefinite. Hence, for any \( x \in \mathbb{R}^m\) , \( \lambda_{\max}(P) x^\top x - x^\top P x \geq 0\) and \( x^\top P x - \lambda_{\min}(P) x^\top x \geq 0\) . By rearranging terms and taking the square root, we know that (46) holds.
Some implications of (5) are as follows. If a function \( \Psi: \mathbb{R}^m \to \mathbb{R}\) is \( L_\Psi\) -Lipschitz with respect to \( \|\cdot\|_P\) , then it is \( L_\Psi \sqrt{\lambda_{\max}(P)}\) -Lipschitz with respect to \( \|\cdot\|\) . Conversely, if \( \Psi\) is \( L'_\Psi\) -Lipschitz with respect to \( \|\cdot\|\) , then it is \( L'_\Psi/\sqrt{\lambda_{\min}(P)}\) -Lipschitz with respect to \( \|\cdot\|_P\) .
The following lemma provides upper bounds related to the square of a nonnegative sequence.
Lemma 6
Suppose that a nonnegative sequence \( (a_k)_{k\in \mathbb{N}}\) satisfies \( a_{k+1} \leq c a_k + b_k, \forall k \in \mathbb{N}\) , where \( c \in (0,1), a_k, b_k \in \mathbb{R}\) . Then,
(47.a)
(47.b)
Proof
We establish a recursive inequality of \( (a_k^2)_{k \in \mathbb{N}}\) as follows
where the last inequality holds because \( 2ab \leq t^2a^2 + \frac{b^2}{t^2}, \forall a,b \in \mathbb{R},t>0\) . Hence, (47.a) is proved. We sum up both sides of (47.a) for \( k=0,…,T-1\) and obtain
It follows that
We multiply both sides of the above inequality by \( 2/(1-c^2)\) and arrive at (47.b).
We present a useful inequality relating the arithmetic and quadratic means. It can be proved by the Cauchy-Schwarz inequality or Jensen’s inequality.
Lemma 7
Consider \( K \in \mathbb{N}{+}\) real numbers \( X_1, …, X_K \in \mathbb{R}\) . Then, \( \frac{1}{K} \sum_{i=1}^{K} X_i \leq \sqrt{\frac{\sum_{i=1}^K X_i^2}{K}}\) .
The following lemma uses the Wasserstein distance between distributions to give an upper bound on the difference between the expectations of a Lipschitz function under these distributions. It is a corollary of the Kantorovich–Rubinstein theorem [5, Particular case 5.16].
Lemma 8 ({[15, Lemma D.4]})
Consider a metric space \( (\mathbb{R}^m,c)\) . Let \( \mu,\nu \in \mathcal{P}_1(\mathbb{R}^m)\) , and let \( \Psi:\mathbb{R}^m \to \mathbb{R}^n\) be \( L_\Psi\) -Lipschitz, i.e., \( \forall x,y \in \mathbb{R}^m, \|\Psi(x) - \Psi(y)\| \leq L_\Psi c(x,y)\) . With \( W_1(\mu,\nu)\) defined by (2), we have
(48)
Next, we present Hölder’s inequality for probability measures. It enables us to bound the expectation of the product of random variables.
Lemma 9 (Hölder’s inequality)
Consider \( K \in \mathbb{N}_{+}\) random variables \( X_1,…,X_K \in \mathbb{R}\) . Let constants \( p_1,…,p_K > 0\) satisfy \( \sum_{i=1}^{K} 1/p_i = 1\) . Then, \( \mathrm{ \mathbb{E} }\left[\left|\prod_{i=1}^{N}X_i \right|\right] \leq \prod_{i=1}^{N} \left(\mathrm{ \mathbb{E} }\left[|X_i|^{p_i}\right]\right)^{\frac{1}{p_i}}\) .
For a set of random variables endowed with tail bounds, we can quantify the probability that their sums do not exceed a certain threshold, as discussed in the following lemma.
Lemma 10
Suppose that \( K \in \mathbb{N}_{+}\) random variables \( X_i \in \mathbb{R}\) satisfy \( \Pr\left(X_i \leq a_i\right) \geq 1 - \tau_i\) , where \( i \in \{1,…,K\}\) , with constants \( a_i \in \mathbb{R}\) and \( \tau_i \in (0,1)\) such that \( \sum_{i=1}^{K} \tau_i \in (0,1)\) . Then, we obtain \( \Pr\left(\sum_{i=1}^{K} X_i \leq \sum_{i=1}^{K} a_i\right) \geq 1-\sum_{i=1}^{K} \tau_i\) .
Proof
Let \( A_i\) denote the event that \( X_i \leq a_i\) . Its complementary event \( A_iĉ\) is \( X_i > a_i\) . The condition of the lemma implies that \( \forall i \in \{1,…,K\}, \Pr\left(A_iĉ\right) \leq \tau_i\) . Then,
where (a.1) follows from Boole’s inequality. Consequently,
where (a.1) holds because the event \( X_i \leq a_i, \forall i \in \{1,…,K\}\) implies that \( \sum_{i=1}^{K} X_i \leq \sum_{i=1}^{K} a_i\) , but not vice versa.
B Proof of (1)
Proof
Thanks to independent \( p_0^1, …, p_0^{n_\textup{{mb}}}\) , independent \( d^1, …, d^{n_\textup{{mb}}}\) , and the dynamics (3), the samples \( p_k^1, …, p_k^{n_\textup{{mb}}}\) collected at time \( k\) are independent when conditioned on \( \mathcal{F}_{k-1}\) . Hence, the mini-batch stochastic gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) given in (11) satisfies
(49)
(50)
where the last equality is due to (8). Furthermore, if (4) is satisfied,
(51)
(52)
where (a.1) holds because \( p_k^1, …, p_k^{n_\textup{{mb}}}\) are independent when conditioned on \( \mathcal{F}_{k-1}\) , and for any random variable \( \xi \in \mathbb{R}^n\) and real number \( a \in \mathbb{R}\) , \( \operatorname{Var}[a\xi] = \mathrm{ \mathbb{E} }\left[\|a\xi\|^2\right] - \left\|\mathrm{ \mathbb{E} }[a\xi]\right\|^2 = a^2 \operatorname{Var}[\xi]\) ; (a.2) follows from (4). Therefore,
where the last inequality uses (49) and (51). Consequently, (1) is proved.
C Proofs for (4.1)
C.1 Proof of (2)
Proof
The joint distributions \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) lie in the metric space \( (\mathbb{R}^{m+r},c)\) with the metric \( c\) given by (15). Hence,
(53)
In (53), (a.1) holds because \( f^{(k)}\) and \( h\) are continuous and hence Borel maps, allowing us to use the property of the pushforward operation, see [58, Proposition 3]. In (a.2), \( \tilde{\beta}\) is a specific coupling in \( \Gamma(\alpha(p_0,d), \mu_d(d'))\) , and \( \pi_1\) and \( \pi_2\) denote the projections on the first and second variables, respectively, i.e., \( \pi_1: (p_0,d,d') \mapsto p_0\) and \( \pi_2: (p_0,d,d') \mapsto d\) . Consequently, the joint distribution of the first two variables of \( \big((\pi_1,\pi_2,\pi_2)_{\#} \tilde{\beta}\big)(p_0,d,d')\) , namely \( (\pi_1,\pi_2)_{\#} \beta\) , is \( \alpha\) , and the marginal distribution of the last variable is \( \mu_d\) . Since \( \big((\pi_1,\pi_2,\pi_2)_{\#} \tilde{\beta}\big)(p_0,d)\) is also a coupling in \( \Gamma(\alpha(p_0,d), \mu_d(d'))\) , (a.2) is true. Further, (a.3) invokes the change of variable formula for pushforward measures. Moreover, (a.4) follows from the fact that the integrand is independent of \( d'\) , allowing the integration to be performed with respect to the joint distribution \( \alpha\) of \( p_0\) and \( d\) . Finally, (a.5) leverages the metric \( c\) in (15), where the distance related to the second component is zero for the same \( d\) . Therefore, (16.a) is proved.
We proceed to establish a recursive inequality of \( V_k\) . For any \( k \in \mathbb{N}_{+}\) ,
(54)
(55)
where (a.1) is due to the distribution dynamics (3) and the steady state \( h(u_k,d)\) satisfying the fixed-point equation \( f(h(u_k,d),u_k,d) = h(u_k,d)\) ; (a.2) leverages the property that \( f\) is \( L_f^p\) -Lipschitz in \( p\) , see (1); (a.3) uses the triangle inequality. In (54), term ➀ corresponds to \( V_k\) , and term ➁ can be bounded from above by
where (a.1) uses (5) in (A); (a.2) follows from the fact that \( h\) is \( L_hû\) -Lipschitz in \( u\) , see the discussion below (1); (a.3) is due to \( \int 1 \,\mathrm{d} \alpha(p_0,d) = 1\) . We incorporate this upper bound into (54) and prove (16.b).
Finally, we demonstrate that the initial upper bound \( V_0\) on \( W_1(\gamma_0,\gamma_\textup{ss}(u_0))\) is finite. Note that
(56)
(57)
where (a.1) follows from the definition \( f^{(0)}(p_0,d) = p_0\) ; (a.2) uses (5) in (A); (a.3) is due to the triangle inequality; (a.4) holds because the integrands only depend on the corresponding random variables and not on their joint distribution. In (56), term ➀ is finite thanks to \( \mu_0 \in \mathcal{P}_1(\mathbb{R}^m)\) , implying that \( \mu_0\) admits a finite absolute moment. We now show that term ➁ in (56) is finite. In fact,
where (a.1) invokes the triangle inequality, and (a.2) holds because \( h(u_0,d)\) is \( L_h^d\) -Lipschitz in \( d\) and \( \int_{\mathbb{R}^r} 1 \,\mathrm{d} \mu_d(d) = 1\) . We know that \( \int_{\mathbb{R}^r} \|d\| \,\mathrm{d} \mu_d(d)\) is finite due to \( \mu_d \in \mathcal{P}_1(\mathbb{R}^r)\) . Since both terms ➀ and ➁ in (56) are finite, the initial bound \( V_0\) is also finite.
C.2 Proof of (1)
Proof
For any \( k \in \mathbb{N}\) , the Wasserstein distance \( W_1(\gamma_k,\gamma_\textup{ss}(u_k))\) is always nonnegative, because the metric \( c\) given in (15) will not be negative. Therefore, the corresponding upper bound \( V_k\) is also nonnegative. Hence, we start from (16.b) in (2), apply (47.b) in (6), and obtain
where \( \rho_1\) and \( \rho_2\) are given in (1). The upper bound (16.a) and the non-negativity of the Wasserstein distance imply that \( 0 \leq W_1(\gamma_k,\gamma_\textup{ss}(u_k)) \leq V_k\) , which leads to
(58)
Therefore, (17) holds. The update rule (10) indicates that \( u_k - u_{k-1} = -\eta\widehat{\nabla}_\textup{{mb}}^{k-1}(u_{k-1})\) . We incorporate this expression into (17) and arrive at (18).
C.3 Proof of (3)
Proof
Let \( u_k \in \mathbb{R}^n\) be given. Consider the following function \( \Psi: \mathbb{R}^{m} \times \mathbb{R}^r \to \mathbb{R}^n\) representing the full gradient inside the expectations in (8) and (12)
We now demonstrate that \( \Psi(p,d)\) is Lipschitz continuous in \( (p,d)\) with respect to the metric \( c\) defined in (15). For any \( p_1,p_2 \in \mathbb{R}^m\) and \( d_1,d_2 \in \mathbb{R}^r\) ,
where (a.1) follows from the triangle inequality; (a.2) uses the fact that norms are sub-multiplicative and the triangle inequality; (a.3) invokes the Lipschitz continuity of \( \nabla_u h(u_k,d)\) , \( \nabla_u \Phi(u_k,p)\) , \( \nabla_p \Phi(u_k,p)\) , \( \Phi(u_k,p)\) , and \( h(u_k,d)\) thanks to (1,2), indicating \( \|\nabla_p \Phi(u_k,p_2)\| \leq L_\Phi^p\) and \( \|\nabla_u h(u_k,d_2)\| \leq L_hû\) ; (a.4) uses (46) in (5) to link with the weighted norm \( \|\cdot\|_P\) . Afterward, we leverage (8) in (A) to obtain (21).
D Proofs for (4.2)
D.1 Proof of (2)
The overarching idea is to analyze the coupled evolution of the distribution dynamics (3) and the algorithm (10). To this end, we first quantify the cumulative Wasserstein metric related to the distribution (3). Afterward, we focus on the iterative update of the algorithm (10) and synthesize the overall convergence measure, i.e., the average expected second moment of gradients.
We start with the following lemma that characterizes the cumulative sum of the squared Wasserstein distances between the distribution at each time and the corresponding steady-state distribution. It is built on (2) and further uses the condition (22) of the step size in (2), thereby exposing the true gradient \( \nabla \tilde{\Phi}(u_k)\) in the upper bound on this cumulative sum.
Lemma 11
Under the conditions of (2), we have
(59)
Proof
We first prove the following intermediate inequality
(60)
where the coefficients \( \rho_1\) and \( \rho_2\) are specified in (1). We know from the update rule (10) that \( u_k - u_{k-1} = -\eta \widehat{\nabla}_\textup{{mb}}^{k-1} \tilde{\Phi}(u_{k-1})\) . We plug this expression into (16.b), invoke (47.a) in (6), (A) (note that \( (V_k)_{k \in \mathbb{N}}\) is a nonnegative sequence, see (C.2)), and obtain
(61)
Recall that \( \mathcal{F}_k\) is the \( \sigma\) -algebra generated by \( \widehat{\nabla}_\textup{{mb}}^{0} \tilde{\Phi}(u_0), …, \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) . It follows that
where (a.1) is due to (14) in (1). We further take the total expectation of both sides of the above inequality, use the tower rule, and arrive at
Moreover, we leverage (47.b) in (6), (A) and (58) to obtain the inequality (60).
We now focus on the last term of (60). Recall from (8) and (12) in (3.1) that \( \nabla \tilde{\Phi}(u_k)\) and \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) are the true gradient and the approximate gradient at \( u_k\) , respectively. Moreover, \( e_k\) is the difference of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) and \( \nabla \tilde{\Phi}(u_k)\) , see (19). Therefore,
(62)
(63)
where (a.1) uses the inequality \( \|a+b\|^2 \leq 2\|a\|^2 + 2\|b\|^2, \forall a,b \in \mathbb{R}^n\) , and (a.2) applies (21) in (3). We plug this upper bound into (60), rearrange terms, and obtain
(64)
(65)
The parametric condition (22) of (2) leads to \( \frac{2\eta^2\rho_2L^2}{1-\rho_1} \left(\frac{M_V}{n_\textup{{mb}}} + 1\right) \leq \frac{1}{7 T} \leq \frac{1}{7}\) . It follows that
We divide both sides of (64) by \( 1 - \frac{2\eta^2\rho_2L^2}{1-\rho_1} \left(\frac{M_V}{n_\textup{{mb}}} + 1\right)\) , use the above upper bounds on coefficients, and obtain (59).
With (11) in hand, we are ready to prove (2).
Proof
Since \( \tilde{\Phi}(u)\) is \( L\) -smooth, we have
(66)
(67)
where (a.1) follows from the update \( u_{k+1} - u_k = -\eta \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) , see (10). Hence,
(68)
(69)
where (a.1) uses \( \mathrm{ \mathbb{E} }[\widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k) \big| \mathcal{F}_{k-1}] = \widehat{\nabla}^k \tilde{\Phi}(u_k)\) , see (13); (a.2) uses the equality \( \widehat{\nabla}^k \tilde{\Phi}(u_k) = \nabla\tilde{\Phi}(u_k) + e_k\) (see (19)) and the upper bound (14); (a.3) follows from the inequalities
We take expectation of both sides of (68), use the tower rule, and obtain
We sum up both sides of the above inequality for \( k=0,…,T-1\) , reorganize terms, and obtain
(70)
The parametric condition (22) of (2) ensures that \( \frac{\eta}{2} - L\eta^2\left(\frac{M_V}{n_\textup{{mb}}} + 1\right) \geq \frac{\eta}{4}\) and \( \frac{\eta}{2} + L\eta^2\left(\frac{M_V}{n_\textup{{mb}}} + 1\right) \leq \frac{3}{4}\eta\) . We leverage (21) and obtain
(71)
Furthermore, we invoke (59) in (11). Hence, we establish the following upper bound
We multiply both sides of the above inequality by \( 8/(\eta T)\) and arrive at
where we additionally use the fact that \( \mathbb{E}[\tilde{\Phi}(u_T)] \geq \tilde{\Phi}^*\) , because \( \tilde{\Phi}^*\) is the optimal value of problem (6). Therefore, (23) and (24) are proved.
D.2 Proof of (1)
Proof
We know from (62) in (D.1) that
Furthermore, we leverage (11) in (D.1) to obtain
By invoking (23) and (24), we prove (25).
D.3 Proof of (3)
Proof
We first derive the following upper bound
where (a.1) follows from (11) in (D.1), and (a.2) invokes the upper bound (23) in (2). Furthermore, (7) in (A) implies that
We combine the above inequalities and prove (3).
E Proofs for (4.3)
E.1 Proof of (4)
The proof resembles what we have presented in (D.1). The key idea is to quantify the coupled evolution of optimization iterations and dynamic distributions. However, to establish convergence with high probability rather than in expectation, we will derive and exploit some tail bounds related to stochastic errors of gradients.
Throughout this subsection, we rely on the following decomposition
(72)
where \( e_k\) and \( \xi_k\) are given in (19) and (27), respectively. Specifically, \( e_k\) denotes the difference of expected gradients (i.e., \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) and \( \nabla \tilde{\Phi}(u_k)\) ) arising from the discrepancy between \( \gamma_k\) and \( \gamma_\textup{ss}(u_k)\) , and \( \xi_k\) indicates the stochastic noise in the mini-batch gradient \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) relative to its expectation \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) .
Along with the iteration (10), the stochastic noise \( \xi_k\) (27) exerts a cumulative influence on the accuracy of solutions. In the following lemma, we provide high-probability bounds on some cumulative quantities that involve \( \xi_k\) and are relevant to the overall convergence measure.
Lemma 12
Let (5) hold. For any \( \tau_1,\tau_2 \in (0,1)\) and \( \lambda > 0\) , the iteration (10) ensures
(73.a)
(73.b)
with probabilities at least \( 1-\tau_1\) and \( 1-\tau_2\) , respectively.
Proof
Recall that \( \mathcal{F}_k\) is the \( \sigma\) -algebra generated by \( \widehat{\nabla}_\textup{{mb}}^{0} \tilde{\Phi}(u_0),…,\widehat{\nabla}_\textup{{mb}}^{k}\tilde{\Phi}(u_k)\) . Hence, as a function of \( \widehat{\nabla}_\textup{{mb}}^{0} \tilde{\Phi}(u_0),…,\widehat{\nabla}_\textup{{mb}}^{k-1} \tilde{\Phi}(u_{k-1})\) determined by the update (10), \( u_k\) is measurable with respect to \( \mathcal{F}_{k-1}\) . Moreover, when conditioned on \( \mathcal{F}_{k-1}\) , \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) is an unbiased estimate of \( \widehat{\nabla}^k \tilde{\Phi}(u_k)\) , see (13). Therefore,
Hence, \( \big(-\nabla \tilde{\Phi}(u_k)^\top \xi_k\big)_{k\in \mathbb{N}}\) is a martingale difference sequence. Furthermore, \( \sigma_\textup{{mb}}\|\nabla\tilde{\Phi}(u_k)\|\) is measurable with respect to \( \mathcal{F}_{k-1}\) , and
where (a.1) uses the Cauchy-Schwarz inequality, and (a.2) is due to (28). Then, we apply the martingale concentration inequality [see 7, Lemma 1] and obtain (73.a).
We proceed to prove (73.b). Let \( \overline{\sigma}_\textup{{mb}} \triangleq \sqrt{T}\sigma_\textup{{mb}} > 0\) . We note that
(74)
(75)
where (a.1) follows from Hölder’s inequality, see (9) in (A), and (a.2) uses (28). We know from the law of total expectation that
Therefore, for any constant \( a>0\) ,
where (a.1) holds because of Markov’s inequality, and (a.2) uses (74). For any fixed \( \tau_2 \in (0,1)\) , we set \( a = T \sigma_\textup{{mb}}^2 \big(1+\ln \frac{1}{\tau_2}\big)\) . It follows that (73.b) holds.
Similar to (11), the following lemma provides an upper bound on the cumulative squared Wasserstein distances. This cumulative sum quantifies the evolution of the distribution driven by the decision-maker. Due to the coupling between the distribution dynamics and the decision, the upper bound involves quantities related to gradients, which originate from optimization iterations.
Lemma 13
Under the conditions of (4), we have
(76)
Proof
We rely on (18) in (1), (4.1) and proceed by deriving an upper bound on the cumulative squared norm of \( \widehat{\nabla}_\textup{{mb}}^{k} \tilde{\Phi}(u_k)\) . Based on (72), we know
(77)
(78)
where (a.1) uses the inequality \( \forall a,b,c \in \mathbb{R}^n, \|a+b+c\|^2 \leq 3(\|a\|^2+\|b\|^2+\|c\|^2)\) , which is a vector-form extension of (7) in (A), and (a.2) follows from (21). We plug (77) into the right-hand side of (18), rearrange terms, and obtain
(79)
The parametric condition (29) of (4) ensures that \( \frac{3\eta^2\rho_2L^2}{1-\rho_1} \leq \frac{1}{7T} \leq \frac{1}{7}\) , which leads to
We divide both sides of (79) by \( 1 - \frac{3\eta^2\rho_2L^2}{1-\rho_1}\) , use the above bounds on coefficients, and obtain (76).
We give the complete proof of (4). The key idea is to synthesize the convergence measure (i.e., the average second moment of gradients) from optimization iterations and the characterization of distribution dynamics in (13). We also leverage the high-probability bounds in (12).
Proof
We incorporate (72) into (66) and have
where (a.1) follows from the inequality \( -\nabla\tilde{\Phi}(u_k)^\top e_k \leq \frac{1}{2}\|\nabla\tilde{\Phi}(u_k)\|^2 + \frac{1}{2} \|e_k\|^2\) , (77), and (21). We sum up both sides of the above inequality for \( k=0,…,T-1\) , reorganize terms, and obtain
The parametric condition (29) of (4) guarantees that \( \frac{\eta}{2} - \frac{3}{2} L\eta^2 \geq \frac{\eta}{4}\) and \( \frac{\eta}{2} + \frac{3}{2} L\eta^2 \leq \frac{3}{4}\eta\) . Furthermore, we use the fact that \( \tilde{\Phi}(u_T)\) is not less than the optimal value \( \tilde{\Phi}^*\) of problem (6), incorporate the upper bound (76), rearrange terms, and arrive at
(80)
For terms ➀ and ➁ in (80), we exploit the high-probability bounds in (12). Specifically, we select \( \tau_1 = \tau_2 = \tau/2\) and apply both (10,12). Then, with probability at least \( 1-\tau\) ,
(81)
Since \( \lambda\) can be any positive constant, we select \( \lambda = \frac{1}{12\sigma_\textup{{mb}}^2}\) . We then plug (81) into (80) and know that with probability at least \( 1-\tau\) ,
We multiply both sides of the above inequality by \( 16/(\eta T)\) and arrive at
which holds with probability at least \( 1-\tau\) . Hence, (4) is proved.
E.2 Proof of (5)
Proof
Starting from (13) in (E.1), we know that
(82)
(4) in (4.3) indicates that with probability at least \( 1 - \frac{\tau}{2}\) ,
(83)
Moreover, (12) in (E.1) implies that with probability at least \( 1 - \frac{\tau}{2}\) ,
(84)
By incorporating the high-probability bounds (83) and (84) into (82) and using (10) in (A), we know that with probability at least \( 1-\tau\) ,
To link with the non-squared Wasserstein distance, we apply (7) in (A) and obtain
F Proofs for (4.4)
F.1 Proof of (4)
We rely on the concentration of the empirical measure evaluated by Wasserstein distances [55]. Such a concentration is concerned with the closeness between \( \mu_d\) and \( \mu_d^N\) with high probability. Since \( \mu_d,\mu_d^N \in \mathcal{P}(\mathbb{R}^r)\) , we define \( W_1(\mu_d,\mu_d^N)\) as
(85)
The measure concentration argument is delineated in the following lemma.
Lemma 14 (from {[55, Theorem 2]})
Let the conditions of (4) hold. Then, for any \( N \geq 1\) ,
where \( c_1\) and \( c_2\) are positive constants that only depend on \( r,\theta,\kappa\) , and \( \mathcal{E}_{\theta,\kappa}(\mu_d)\) .
The proof of (4) is as follows.
Proof
The empirical objective \( \tilde{\Phi}^N(u)\) can be equivalently written as \( \tilde{\Phi}^N(u) = \mathrm{ \mathbb{E} }_{p \sim \mu_\textup{ss}^N(u)}[\Phi(u,p)]\) . Accordingly, the gradient \( \nabla \tilde{\Phi}^N(u)\) involves the empirical distribution \( \gamma_\textup{ss}^N(u)\) . For any \( u \in \mathbb{R}^n\) , in terms of the difference between the gradients given the distribution \( \gamma_\textup{ss}(u)\) and the empirical distribution \( \gamma_\textup{ss}^N(u) \triangleq (h(u,\cdot), \mathopen{}\mathrm{Id})_{\#} \mu_d^N\) , we have
(86)
where (a.1) is similar to (21) in (3), (4.1). We derive (a.2) in (86) as follows. Let \( \overline{\beta}^*\) be an optimal coupling of \( (\mu_d,\mu_d^N)\) in the sense of (85), i.e., \( \int \|d - d'\| \,\mathrm{d} \overline{\beta}^*(d,d') = W_1(\mu_d,\mu_d^N)\) . Such an optimal coupling exists, see [5, Theorem 4.1] for a formal proof. Then,
where (a.1) follows from the property of the pushforward operation [58, Proposition 3], and the metric \( c\) is given by (15); (a.2) holds because \( \overline{\beta}^*\) is a specific coupling of \( (\mu_d,\mu_d^N)\) , i.e., \( \overline{\beta}^* \in \Gamma(\mu_d,\mu_d^N)\) ; (a.3) uses the expression (15); (a.4) leverages the property that \( h(u,d)\) is \( L_h^d\) -Lipschitz in \( d\) and (46) in (5), (A); (a.5) is true because \( \overline{\beta}^*\) is an optimal coupling of \( (\mu_d,\mu_d^N)\) . Since (86) holds for any \( u \in \mathbb{R}^n\) , we plug in \( \{u_0^N, …, u_{T-1}^N\}\) and know that
(87)
(88)
Furthermore, (14) ensures that with probability at least \( 1 - \frac{\tau}{2}\) ,
(89)
We combine (89) with (87) and prove (4).
F.2 Proof of (6)
Proof
The key idea is to start from the decomposition (33) and then leverage the high-probability bounds on the generalization error (see (4)) and the optimization error (see (4)).
We exploit (33) in (4.4) to obtain
(90)
(4) provides the following upper bounds on term ➀ in (90):
(91)
which hold with probability at least \( 1-\tau/2\) . For term ➁ in (90), we invoke (4) and know that with probability at least \( 1-\tau/2\) ,
(92)
Supported by (10), we combine the upper bounds (91) and (92) and prove (6).
G Proof for (5)
G.1 Proof of (7)
We first present a lemma of the angles between vectors involving conic combinations.
Lemma 15
Consider any nonzero vectors \( v_1, v_2 \in \mathbb{R}^m\) that form an acute angle \( \theta_{12} \in (0, \frac{\pi}{2})\) . Let \( v_3 = \lambda_1 v_1 + \lambda_2 v_2\) be a conic combination of \( v_1\) and \( v_2\) , where \( \lambda_1, \lambda_2 \geq 0\) . Then, the angle \( \theta_{23}\) between \( v_3\) and \( v_2\) is not more than \( \theta_{12}\) . Moreover, if \( \lambda_1,\lambda_2 > 0\) , then \( \theta_{23}\) is smaller than \( \theta_{12}\) .
Proof
Without loss of generality, we consider \( v_1\) and \( v_2\) of unit norm. If not, we can normalize these vectors and perform a similar analysis. Let \( \overline{v}_3 = \overline{\lambda}_1 v_1 + \overline{\lambda}_2 v_2\) be the normalized vector of \( v_3\) , where \( \overline{\lambda}_1 = \lambda_1/\|v_3\|\) , and \( \overline{\lambda}_2 = \lambda_2/\|v_3\|\) . It follows that
(93)
Since unit vectors \( v_1\) and \( v_2\) form an acute angle, we know \( 0< v_1^\top v_2 < 1\) . Therefore,
which leads to \( \overline{\lambda}_1 + \overline{\lambda}_2 \geq 1\) and \( 0 \leq \overline{\lambda}_1, \overline{\lambda}_2 \leq 1\) . Then,
where (a.1) and (a.2) hold because \( v_1\) , \( v_2\) , and \( \overline{v}_3\) are unit vectors; (a.3) leverages (93) to rewrite \( v_1^{\top} v_2\) ; (a.4) uses the fact that \( \overline{\lambda}_1\) , \( \overline{\lambda}_1+\overline{\lambda}_2-1\) , and \( \overline{\lambda}_2+1-\overline{\lambda}_1\) are nonnegative, because \( \overline{\lambda}_2 + 1 - \overline{\lambda}_1 \geq \overline{\lambda}_2 \geq 0\) . It follows from the monotonicity of the cosine function on \( [0,\pi]\) that \( \theta_{23} \leq \theta_{12}\) . If \( \lambda_1\) and \( \lambda_2\) are strictly positive, then \( \overline{\lambda}_1\) and \( \overline{\lambda}_2\) lie in \( (0,1)\) , and \( \overline{\lambda}_1 + \overline{\lambda}_2 > 1\) . In this case, \( \cos(\theta_{23}) - \cos(\theta_{12})\) becomes positive, and therefore \( \theta_{23} < \theta_{12}\) .
(15) formalizes the geometric intuition that if a vector lies in a conic region bounded by two vectors forming an acute angle, then this vector is closer to one of the boundary vectors than two boundary vectors are to each other. We provide the proof of (7) as follows.
Proof
We divide the proof into three parts. First, we prove the existence and uniqueness of the steady state \( p_\textup{ss}\) of the polarized dynamics (34). We then derive the steady-state sensitivity of (34). Finally, we quantify how the coefficients \( \lambda\) and \( \sigma\) in (34) influence the closeness between \( p_\textup{ss}\) and \( q\) (or \( -q\) ), an indicator of the steering ability of the decision-maker.
Existence and uniqueness of \( p_\textup{ss}\) : Note that the initial state \( p_0\) is nonzero, because \( \|p_0\|=1\) . We first address the special case in (3), i.e., \( p_0^\top q = 0\) . The dynamics (34) indicate that \( p_k = p_0 \neq 0, \forall k \in \mathbb{N}\) . Therefore, the steady state exists and is unique: it equals \( p_0\) . In another special case where \( p_0\) and \( q\) are parallel, the unique steady state is either \( q\) or \( -q\) , depending on \( \sigma\) , \( \|q\|\) , and if \( p_0\) and \( q\) are of the same or opposite direction.
We proceed to analyze the case in (4), i.e., \( p_0^\top q > 0\) and \( p_0\) and \( q\) are not parallel. Let \( \mathrm{sgn}(\cdot)\) denote the sign function, i.e., \( \mathrm{sgn}(x)\) equals \( -1\) , \( 0\) , or \( 1\) if \( x<0\) , \( x=0\) , or \( x>0\) , respectively. The initial condition satisfies \( \mathrm{sgn}(p_0^\top q) = 1\) . Suppose that for a particular \( k \in \mathbb{N}\) , \( p_k^\top q > 0\) holds. It follows from the dynamics (34) that
(94)
where (a.1) uses the base case \( p_0^\top q > 0\) and the induction hypothesis \( p_k^\top q > 0\) . The above derivation is similar to [23, Proof of Propostion 1]. Hence, \( p_{k+1}^\top q > 0\) also holds. Therefore, for any \( k \in \mathbb{N}\) , \( p_k^\top q > 0\) , implying \( p_k\) is nonzero and that \( p_k\) and \( q\) always form an acute angle. Let \( p_k^+ \triangleq (1-\lambda)p_0 + \sigma \cdot (p_k^{\top} q) q\) be an intermediate vector. We now prove the following proposition on the angles related to \( p_k, p_{k+1}\) , and \( p_k^+\) illustrated by (17).

In the base case when \( k=0\) , \( p_0^+\) is a conic combination of \( p_0\) and \( q\) , and \( p_1\) is a conic combination of \( p_0\) and \( p_0^+\) . Therefore, (15) ensures that (1) holds. Suppose that (1) is true for a particular \( k \in \mathbb{N}\) . Because \( p_k\) and \( p_{k+1}\) are of unit norm and the angle between \( p_{k+1}\) and \( q\) is smaller than that between \( p_k\) and \( q\) , we know that \( 0 < p_{k}^\top q < p_{k+1}^\top q\) . Hence,
where (a.1) uses the expression of \( p_k^+\) . Since \( p_{k+1}^+\) is a conic combination of \( p_k^+\) and \( q\) and the combination coefficients are positive, we know from (15) that the angle between \( p_{k+1}^+\) and \( q\) is smaller than that between \( p_k^+\) and \( q\) , which is further smaller than that between \( p_{k+1}\) and \( q\) (c.f. the induction hypothesis). Finally, \( p_{k+2}\) lies in the convex cone formed by \( p_{k+1}\) and \( p_{k+1}^+\) . Hence, (1) also holds true for \( k+1\) . Therefore, (1) is proved.
A consequence of (1) is that the angle between \( p_k\) and \( q\) is monotonically decreasing as \( k\) increases. Additionally, this angle is bounded from below by zero, because \( p_k\) always lies in the convex cone formed by \( p_0\) and \( q\) . The monotone convergence theorem ensures that there exists a unique steady state \( p_\textup{ss}\) , i.e., the limiting point of \( p_k\) .
The analysis for the case in (5) (i.e., \( p_0^\top q < 0\) ) is similar to the above analysis for (4) (i.e., \( p_0^\top q > 0\) ) by considering the convex cone formed by \( p_0\) and \( -q\) , or put differently, the angle between \( p_k\) and \( -q\) for different \( k\) .
Derivation of the steady-state sensitivity: The steady state of the dynamics (34) satisfies
(95.a)
We have proved that \( p_\textup{ss}\) (and also \( \tilde{p}_\textup{ss}\) ) are nonzero, see the reasoning about (94). Hence,
We further apply (5) and obtain the steady-state sensitivity as follows

The influence of coefficients: We quantify how the coefficients \( \lambda\) and \( \sigma\) in (34) determine the steering ability of the decision-maker, which is reflected by the angle \( \overline{\theta}\) between \( p_\textup{ss}\) and \( q\) (or \( -q\) ). We consider the case where \( p_0^\top q > 0\) and \( p_0\) and \( q\) are not parallel, and a similar reasoning applies to the case of \( p_0^\top q < 0\) . Let \( \phi \in (0,90^\circ)\) denote the angle between \( p_0\) and \( q\) . Note that \( p_0\) and \( p_\textup{ss}\) are of unit norm. Since \( p_\textup{ss}\) satisfies the fixed-point equation (95), the vector \( (1-\lambda) p_0 + \sigma\cdot(p_\textup{ss}^\top q) q\) (i.e., \( (1-\lambda) p_0 + \sigma\|q\|^2 \cos(\overline{\theta})q\) ) is collinear with \( p_\textup{ss}\) , see (18). While this illustration and the following analysis are for two-dimensional vectors, extensions can be derived for high-dimensional scenarios. We analyze the triangle in (18) and use the law of sines to obtain
where (a.1) invokes the double angle formula \( \sin(2\overline{\theta}) = 2\sin(\overline{\theta})\cos(\overline{\theta})\) . Note that \( \sin(2\overline{\theta})/\sin(\phi-\overline{\theta})\) is an increasing function of \( \overline{\theta}\) . The increase of \( \lambda \in [0,1]\) and \( \sigma > 0\) result in the decrease of \( \overline{\theta}\) , implying a stronger steering ability of the decision-maker.
References
[1] Decision-dependent probabilities in stochastic programs with recourse Computational Management Science 2018 15 3 369–395
[2] Distributionally robust optimization with decision dependent ambiguity sets Optimization Letters 2020 14 8 2565–2594
[3] Distributionally robust facility location problem under decision-dependent stochastic demand European Journal of Operational Research 2021 292 2 548–561
[4] Strategic distribution shift of interacting agents via coupled gradient flows Advances in Neural Information Processing Systems 2023 36 45971–46006
[5] Optimal Transport: Old and New Springer 2009 338
[6] Tight analyses for non-smooth stochastic gradient descent Proceedings of the 32nd Conference on Learning Theory 2019 1579–1613
[7] A high probability analysis of adaptive SGD with momentum arXiv preprint arXiv:2007.14294 2020
[8] High Probability Convergence Bounds for Non-convex Stochastic Gradient Descent with Sub-Weibull Noise Journal of Machine Learning Research 2024 25 241 1–36
[9] High probability guarantees for nonconvex stochastic gradient descent with heavy tails Proceedings of the International Conference on Machine Learning 2022 12931–12963
[10] A geometric model of opinion polarization Mathematics of Operations Research 2024 49 1 251–277
[11] Polarization in geometric opinion dynamics Proceedings of the 22nd ACM Conference on Economics and Computation 2021 499–519
[12] Lectures on Stochastic Programming: Modeling and Theory SIAM 2021
[13] Online stochastic optimization with Wasserstein based non-stationarity arXiv preprint arXiv:2012.06961 2020
[14] Online stochastic optimization with time-varying distributions IEEE Transactions on Automatic Control 2021 66 4 1840–1847
[15] Performative prediction Proceedings of the International Conference on Machine Learning 2020 7599–7609
[16] Performative prediction: Past and future arXiv preprint arXiv:2310.16608 2023
[17] Accounting for AI and Users Shaping One Another: The Role of Mathematical Models arXiv preprint arXiv:2404.12366 2024
[18] The impact of recommendation systems on opinion dynamics: Microscopic versus macroscopic effects Proceedings of the 62nd IEEE Conference on Decision and Control 2023 4824–4829
[19] Mitigating Polarization in Recommender Systems via Network-aware Feedback Optimization arXiv preprint arXiv:2408.16899 2024
[20] A tutorial on modeling and analysis of dynamic social networks. Part I Annual Reviews in Control 2017 43 65–79
[21] Learning mean field games: A survey arXiv preprint arXiv:2205.12944 2022
[22] Why are US parties so polarized? A "satisficing" dynamical model SIAM Review 2020 62 3 646–657
[23] Preference dynamics under personalized recommendations Proceedings of the 23rd ACM Conference on Economics and Computation 2022 795–816
[24] Nonlinear Systems Prentice Hall 2002
[25] Learning models with uniform performance via distributionally robust optimization Annals of Statistics 2021 49 3 1378–1406
[26] Distributionally Robust Optimization arXiv preprint arXiv:2411.02549 2024
[27] Stochastic optimization for performative prediction Advances in Neural Information Processing Systems 2020 33 4929–4939
[28] Stochastic optimization with decision-dependent distributions Mathematics of Operations Research 2023 48 2 954–998
[29] Outside the echo chamber: Optimizing the performative risk Proceedings of the International Conference on Machine Learning 2021 7710–7720
[30] Regret minimization with performative feedback Proceedings of the International Conference on Machine Learning 2022 9760–9785
[31] Multiplayer performative prediction: Learning in decision-dependent games Journal of Machine Learning Research 2023 24 202 1–56
[32] Zero-regret performative prediction under inequality constraints Advances in Neural Information Processing Systems 2023 36 1298–1308
[33] How to learn when data reacts to your model: Performative gradient descent Proceedings of the International Conference on Machine Learning 2021 4641–4650
[34] Multi-agent performative prediction with greedy deployment and consensus seeking agents Advances in Neural Information Processing Systems 2022 35 38449–38460
[35] Multi-agent performative prediction: From global stability and optimality to chaos Proceedings of the 24th ACM Conference on Economics and Computation 2023 1047–1074
[36] Stochastic optimization under distributional drift Journal of Machine Learning Research 2023 24 147 1–56
[37] Online projected gradient descent for stochastic optimization with decision-dependent distributions IEEE Control Systems Letters 2022 6 1646–1651
[38] Stochastic saddle point problems with decision-dependent distributions SIAM Journal on Optimization 2023 33 3 1943–1967
[39] State dependent performative prediction with stochastic approximation Proceedings of the International Conference on Artificial Intelligence and Statistics 2022 3164–3186
[40] Performative prediction in a stateful world Proceedings of the International Conference on Artificial Intelligence and Statistics 2022 6045–6061
[41] Decision-dependent risk minimization in geometrically decaying dynamic environments Proceedings of the AAAI Conference on Artificial Intelligence 2022 36 8081–8088
[42] Performative reinforcement learning Proceedings of the International Conference on Machine Learning 2023 23642–23680
[43] Mean field games Encyclopedia of Systems and Control Springer 2021 1197–1202
[44] Model-Based RL for Mean-Field Games is not Statistically Harder than Single-Agent RL Proceedings of the International Conference on Machine Learning 2024
[45] Approximately solving mean field games via entropy-regularized deep reinforcement learning Proceedings of the International Conference on Artificial Intelligence and Statistics 2021 1909–1917
[46] Optimal transport in systems and control Annual Review of Control, Robotics, and Autonomous Systems 2021 4 89–113
[47] Dynamic programming in probability spaces via optimal transport SIAM Journal on Control and Optimization 2024 62 2 1183–1206
[48] Time-varying convex optimization: Time-structured algorithms and applications Proceedings of the IEEE 2020 108 11 2032–2048
[49] Optimization Algorithms as Robust Feedback Controllers Annual Reviews in Control 2024 57
[50] Contraction theory for nonlinear stability analysis and learning-based control: A tutorial overview Annual Reviews in Control 2021 52 135–169
[51] Implicit Functions and Solution Mappings Springer 2009 543 New York
[52] Optimization methods for large-scale machine learning SIAM Review 2018 60 2 223–311
[53] Stochastic first-and zeroth-order methods for nonconvex stochastic programming SIAM Journal on Optimization 2013 23 4 2341–2368
[54] On stochastic gradient Langevin dynamics with dependent data streams: The fully nonconvex case SIAM Journal on Mathematics of Data Science 2021 3 3 959–986
[55] On the rate of convergence in Wasserstein distance of the empirical measure Probability Theory and Related Fields 2015 162 3 707–738
[56] On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming Mathematical Programming 2006 106 25–57
[57] A new one-point residual-feedback oracle for black-box learning and control Automatica 2022 136 110006
[58] Distributional uncertainty propagation via optimal transport arXiv preprint arXiv:2205.00343 2022
[59] Performative Control for Linear Dynamical Systems Advances in Neural Information Processing Systems 2024 37